LLM Observability with OpenTelemetry: Build a Content Moderation API in Python and FastAPI
- 15 hours ago
- 23 min read
Introduction
Content moderation at scale is one of the most operationally demanding problems in AI applications. Rule-based filters miss context and produce too many false positives. Fully manual review does not scale. A large language model can read text the way a human moderator would, understanding tone, context, and intent, and produce structured output that downstream systems can act on automatically.
In this tutorial we build a FastAPI content moderation API that passes every piece of submitted text through a three-stage LLM pipeline: classify the content and assign a severity score, explain why it received that classification, and rewrite flagged content into a safe alternative.
Every API call is instrumented with OpenTelemetry so you can see exactly how long each stage took and what it cost. Stats are saved to disk after every request and accumulate across server restarts with per-session breakdowns.

What We Are Building
A REST API that accepts a POST request with a piece of text and returns:
Label — hate_speech, spam, or safe
Severity score — integer 1–5 (null for safe content)
Categories — specific sub-categories that triggered the label
Explanation — one or two sentences explaining the classification
Rewrite — a cleaned version of flagged content (null for safe content)
Each request runs two or three LLM calls (rewrite is skipped for safe content), emits OpenTelemetry spans to the terminal and to traces.json, and updates stats.json with lifetime and per-session token and cost breakdowns.
Tech Stack
Component | Tool |
API framework | FastAPI |
LLM | gpt-4o-mini (configurable via .env) |
Observability | OpenTelemetry SDK |
Terminal output | Rich |
Environment | python-dotenv |
Project Structure
llm_content_moderator/
├── main.py # FastAPI app with 3-stage pipeline and OpenTelemetry
├── .env # OPENAI_API_KEY and all configuration values
├── requirements.txt
├── stats.json # written after every request — accumulates across restarts
└── traces.json # one entry per OTel span — appended on every request
Setting Up the Environment
Install the required packages:
pip install openai fastapi uvicorn python-dotenv rich opentelemetry-api opentelemetry-sdk opentelemetry-instrumentation-fastapi
All configuration lives in .env:
OPENAI_API_KEY=your_openai_api_key_here
MODERATOR_MODEL=gpt-4o-mini
MODERATOR_TEMPERATURE=0.0
INPUT_COST_PER_TOKEN=0.00000015
OUTPUT_COST_PER_TOKEN=0.00000060
INPUT_COST_PER_TOKEN and OUTPUT_COST_PER_TOKEN store the per-token pricing for the chosen model. When you switch models, you update only the .env file. No code changes needed.
Then load everything at the top of main.py:
import os # read environment variables from .env
import json # parse JSON responses from the LLM
import time # measure latency for each API call
from datetime import datetime # timestamp each call in the log
from dotenv import load_dotenv # load .env before any os.environ.get() call
from openai import OpenAI # official OpenAI Python SDK
from fastapi import FastAPI # web framework that exposes the /moderate endpoint
from pydantic import BaseModel # validates and parses the incoming JSON request body
from rich.console import Console # rich terminal output with color and markup support
from rich.panel import Panel # bordered panel for displaying moderation results
from opentelemetry import trace # access the global tracer
from opentelemetry.sdk.trace import TracerProvider # manages the lifecycle of all spans
from opentelemetry.sdk.trace.export import SimpleSpanProcessor # exports each span immediately when it ends
from opentelemetry.sdk.trace.export import SpanExporter, SpanExportResult # base classes for the custom exporter
from opentelemetry.instrumentation.fastapi import FastAPIInstrumentor # auto-instruments FastAPI with a root HTTP span
load_dotenv() # injects all key=value pairs from .env into os.environ
console = Console() # single rich console instance shared across the whole app
api_key = os.environ.get("OPENAI_API_KEY") # secret key for all OpenAI API calls
mod_model = os.environ.get("MODERATOR_MODEL", "gpt-4o-mini") # model used for all three moderation stages
mod_temp = float(os.environ.get("MODERATOR_TEMPERATURE", 0.0)) # zero temperature for consistent, reproducible decisions
input_cost_per_token = float(os.environ.get("INPUT_COST_PER_TOKEN", 0.00000015)) # per-token USD rate for prompt tokens
output_cost_per_token = float(os.environ.get("OUTPUT_COST_PER_TOKEN", 0.00000060)) # per-token USD rate for completion tokens
if not api_key: # fail fast before any server starts
raise ValueError("Set OPENAI_API_KEY in your .env file before running.") # clear error if the key is missing
Keeping costs in .env rather than hardcoded in the source means you can change models and update pricing in one place. When OpenAI revises its rates, no code change is needed. Update the two values in .env and restart the server.
Session-Aware Stats Tracking
Stats are stored in two in-memory lists that are written to stats.json after every request. On startup, the previous stats.json is loaded so lifetime totals carry over across restarts. Two session-scoped lists track only the calls made in the current server run, enabling per-session cost breakdowns.
call_log = [] # accumulates one record per LLM call — written to stats.json after every request
request_log = [] # accumulates one record per /moderate request — includes label, scores, and full results
try: # restore previous session data so lifetime totals accumulate
with open("stats.json", "r", encoding="utf-8") as f:
_prev = json.load(f)
call_log = _prev.get("calls", []) # reload all previous LLM call records
request_log = _prev.get("requests", []) # reload all previous request records
except (FileNotFoundError, json.JSONDecodeError):
pass # start fresh if no file exists yet or file is corrupt
session_id = datetime.now().isoformat() # unique identifier for this server run
session_call_log = [] # LLM calls made only in this server run — always starts empty on restart
session_request_log = [] # requests handled only in this server run — always starts empty on restart
Every entry appended to call_log is also appended to session_call_log. When save_stats() runs, it computes totals twice: once from call_log for the lifetime view and once from session_call_log for the current session entry in the sessions array.
OpenTelemetry Observability
OpenTelemetry provides distributed tracing. Each stage of the pipeline runs inside a named span, so you can see exactly how long classify, explain, and rewrite each took, what they cost, and how they nest inside the root pipeline span. We use two custom exporters: one that prints spans to the terminal in a readable format, and one that appends them to traces.json for persistence.
PrettySpanExporter
class PrettySpanExporter(SpanExporter): # custom exporter that prints a readable trace summary instead of raw JSON
def export(self, spans): # called automatically when each span ends
for span in spans: # iterate over all finished spans in this batch
attrs = { # collect only our custom attributes — skip FastAPI internals
k: v for k, v in (span.attributes or {}).items()
if any(k.startswith(p) for p in ("llm.", "moderation.", "input."))
}
if not attrs: # skip spans that carry no custom attributes (e.g. the HTTP root span)
continue
duration_ms = (span.end_time - span.start_time) / 1_000_000 # nanoseconds → milliseconds
console.print(f"\n [bold cyan][TRACE][/bold cyan] {span.name} [dim]— {duration_ms:.0f} ms[/dim]")
for key, val in attrs.items(): # print each custom attribute
console.print(f" [dim]{key}:[/dim] {val}") # indented key: value
return SpanExportResult.SUCCESS # signal to the SDK that export succeeded
def shutdown(self): # called when the tracer provider shuts down — nothing to flush for a print-based exporter
pass
FileSpanExporter
On every export call, the exporter loads the existing traces.json, appends the new spans, and overwrites the file. A missing file and a corrupt file are both handled the same way: the records list starts empty and the file is written fresh. Every span from every request accumulates across the lifetime of the server, so traces.json grows into a complete history of all pipeline activity.
class FileSpanExporter(SpanExporter): # persists every span to traces.json so traces survive after the server stops
def export(self, spans): # called automatically when each span ends
try: # load whatever is already in the file so we can append to it
with open("traces.json", "r", encoding="utf-8") as f:
records = json.load(f)
except (FileNotFoundError, json.JSONDecodeError):
records = [] # start fresh if the file does not exist or is corrupt
for span in spans:
ctx = span.get_span_context() # read trace_id and span_id
duration_ms = (span.end_time - span.start_time) / 1_000_000 # nanoseconds → milliseconds
records.append({
"trace_id": format(ctx.trace_id, "032x"), # hex trace identifier
"span_id": format(ctx.span_id, "016x"), # hex span identifier
"name": span.name, # e.g. "moderation.classify"
"timestamp": datetime.fromtimestamp(span.start_time / 1_000_000_000).isoformat(), # span start time
"duration_ms": round(duration_ms, 2), # wall-clock duration
"attributes": dict(span.attributes or {}), # all custom key-value attributes
})
with open("traces.json", "w", encoding="utf-8") as f: # overwrite with the updated list
json.dump(records, f, indent=2)
return SpanExportResult.SUCCESS # signal to the SDK that export succeeded
def shutdown(self): # nothing to flush for a file-based exporter
pass
Registering the Exporters
FastAPIInstrumentor.instrument_app(app) automatically wraps every incoming HTTP request in a root span. The three pipeline spans (classify, explain, rewrite) become children of that root span, forming a complete trace tree for every request. PrettySpanExporter filters out the HTTP root span so only the LLM-specific spans appear in the terminal.
provider = TracerProvider() # top-level object that owns all tracers and processors
provider.add_span_processor(SimpleSpanProcessor(PrettySpanExporter())) # print each span to the terminal immediately
provider.add_span_processor(SimpleSpanProcessor(FileSpanExporter())) # also write each span to traces.json
trace.set_tracer_provider(provider) # register as the global provider so all code shares it
tracer = trace.get_tracer("llm_content_moderator", "1.0.0") # named tracer — all spans from this file are grouped under this name
app = FastAPI(title="LLM Content Moderator", version="1.0.0") # creates the ASGI app that uvicorn will serve
FastAPIInstrumentor.instrument_app(app) # auto-adds a root HTTP span for every incoming request
oai = OpenAI(api_key=api_key) # single client instance reused for every LLM call in the pipeline
The LLM Call Wrapper
Every LLM call in the pipeline goes through tracked_call. It sends the request, measures latency, computes cost from the per-token rates in .env, sets all values as span attributes, and appends a full record to both the lifetime and session call logs.
class ModerateRequest(BaseModel): # Pydantic model — FastAPI uses this to validate and parse the POST body
text: str # the content to be moderated — required field
def tracked_call(stage, messages, span): # sends one LLM request, logs usage, and sets span attributes
start = time.time() # start the stopwatch before the HTTP request leaves the process
response = oai.chat.completions.create( # block until the LLM responds
model=mod_model, # the model configured in .env
messages=messages, # full system + user conversation array
temperature=mod_temp, # 0.0 for deterministic moderation decisions
response_format={"type": "json_object"}, # force valid JSON so we can parse directly without error handling
metadata={ # tags visible in the OpenAI dashboard usage logs
"dev_name": "Ganesh",
"project": "codex-test",
"environment": "local",
"purpose": "testing",
},
)
elapsed = round(time.time() - start, 3) # wall-clock latency in seconds
usage = response.usage # token count object from the API response
input_cost = usage.prompt_tokens * input_cost_per_token # cost of the prompt in USD
output_cost = usage.completion_tokens * output_cost_per_token # cost of the completion in USD
total_cost = input_cost + output_cost # combined cost for this single call
span.set_attribute("llm.model", mod_model) # which model handled this stage
span.set_attribute("llm.stage", stage) # pipeline stage name: classify / explain / rewrite
span.set_attribute("llm.tokens.input", usage.prompt_tokens) # prompt token count
span.set_attribute("llm.tokens.output", usage.completion_tokens) # completion token count
span.set_attribute("llm.tokens.total", usage.total_tokens) # combined token count
span.set_attribute("llm.cost.usd", round(total_cost, 7)) # cost for this stage in USD
span.set_attribute("llm.latency_seconds", elapsed) # latency for this stage in seconds
_record = { # build the call record once and share it
"timestamp": datetime.now().isoformat(), # ISO timestamp of when this call ran
"stage": stage, # pipeline stage: classify, explain, or rewrite
"model": mod_model, # model that handled the call
"result": { # nested dict with token and cost breakdown
"prompt_tokens": usage.prompt_tokens, # input tokens for this call
"completion_tokens": usage.completion_tokens, # output tokens for this call
"total_tokens": usage.total_tokens, # combined token count
"input_cost": round(input_cost, 7), # prompt cost in USD
"output_cost": round(output_cost, 7), # completion cost in USD
"total_cost": round(total_cost, 7), # total cost in USD
},
"latency_seconds": elapsed, # wall-clock time for this call
}
call_log.append(_record) # lifetime log — persisted across restarts
session_call_log.append(_record) # current-session log — resets on every restart
return json.loads(response.choices[0].message.content) # parse the JSON string and return a Python dict
The metadata dict is attached to every OpenAI call and appears in the usage logs in the OpenAI dashboard. This lets you filter all calls made by this project, identify costs by environment, and separate test runs from production, without any changes to the API itself.
The 3-Stage Moderation Pipeline
Each stage has a dedicated system prompt that instructs the model to return a specific JSON schema. Using response_format={"type": "json_object"} in tracked_call ensures the model always returns parseable JSON without any manual text stripping.
Stage 1 — Classify
The classifier reads the submitted text and returns a label, a severity score from 1 to 5, and a list of sub-categories that triggered the decision. All three values come back in a single JSON response, so one API call gives us everything we need to decide whether to run the next two stages.
CLASSIFY_PROMPT = """
You are a content moderation system. Classify the given text into exactly one of these labels:
"hate_speech" — promotes hatred, discrimination, or violence against a person or group
"spam" — unsolicited promotional content, scams, or repetitive low-quality text
"safe" — appropriate content that does not violate any policy
Also assign a severity score (1–5) where 1 is mildly concerning and 5 is extremely harmful.
For "safe" content set severity to null.
Respond in valid JSON with exactly these keys:
"label": one of "hate_speech", "spam", "safe"
"severity": integer 1–5 or null
"categories": list of applicable sub-categories or [] if safe
hate_speech sub-categories: ["profanity", "violence", "discrimination", "threat"]
spam sub-categories: ["promotional", "scam", "urgency", "fake_prize", "phishing"]
""".strip()
def classify_content(text, span): # stage 1 — classify the text and score severity
span.set_attribute("input.text_length", len(text)) # record how long the input is on the classify span
messages = [ # build the conversation array for the classifier
{"role": "system", "content": CLASSIFY_PROMPT}, # system prompt defines the three labels and JSON schema
{"role": "user", "content": f"TEXT TO CLASSIFY:\n{text}"}, # user message contains only the raw text
]
result = tracked_call("classify", messages, span) # call the LLM and log usage to the span
span.set_attribute("moderation.label", result.get("label", "")) # write the classification decision to the span
span.set_attribute("moderation.severity", result.get("severity") or 0) # write the severity score to the span
return result # return {"label": ..., "severity": ..., "categories": [...]}
The categories field lists specific sub-categories that triggered the label. For spam this might be ["promotional", "urgency"]; for hate speech, ["discrimination", "threat"]. Providing named examples in the prompt gives the model a vocabulary to draw from rather than inventing its own sub-category names, which makes the output consistent across requests.
Stage 2 — Explain
The explainer receives the original text and the label assigned in Stage 1, then writes one or two sentences describing which specific parts of the text triggered the classification. This runs for every request, including safe content, so every moderation decision has a written reason attached to it.
EXPLAIN_PROMPT = """
You are a content moderation reviewer. Given a piece of text and its classification label,
explain clearly and concisely why it received that label.
Be specific about which parts of the text triggered the classification.
Respond in valid JSON with exactly this key:
"explanation": one or two sentences explaining the classification decision
""".strip()
def explain_classification(text, label, span): # stage 2 — explain why the label was assigned
span.set_attribute("moderation.label_explained", label) # record which label is being explained
messages = [ # build the conversation array for the explainer
{"role": "system", "content": EXPLAIN_PROMPT}, # system prompt defines the explanation task
{"role": "user", "content": f"TEXT: {text}\nLABEL: {label}"}, # user message provides text and label
]
return tracked_call("explain", messages, span) # return {"explanation": "..."}
The explanation stage runs for every request including safe content. For a human reviewer auditing moderation decisions, a written explanation is far more useful than a label alone. It also creates an audit trail showing what reasoning the system applied to each piece of text, which is important for accountability in production deployments.
Stage 3 — Rewrite
The rewriter takes the flagged text and produces a cleaned version that removes harmful or spammy elements while keeping the original intent where possible. This stage only runs when the label from Stage 1 is hate_speech or spam, so safe content exits the pipeline after two calls instead of three.
REWRITE_PROMPT = """
You are a content editor. Rewrite the given text to remove any harmful, offensive, or spammy
elements while preserving the original intent where possible.
If the original intent itself is harmful, produce a neutral and constructive alternative.
Respond in valid JSON with exactly this key:
"rewrite": the cleaned version of the text
""".strip()
def rewrite_content(text, span): # stage 3 — produce a clean version of flagged text
messages = [ # build the conversation array for the rewriter
{"role": "system", "content": REWRITE_PROMPT}, # system prompt defines the rewriting task
{"role": "user", "content": f"TEXT TO REWRITE:\n{text}"}, # user message contains the original flagged text
]
return tracked_call("rewrite", messages, span) # return {"rewrite": "..."}
The rewrite stage runs only when the label is hate_speech or spam. Skipping it for safe content saves one API call per request, roughly a third of the cost for clean traffic. The rewritten text is returned alongside the original label and explanation so the caller can decide whether to use the cleaned version, reject the content entirely, or escalate for human review.
Rich Terminal Output
After every request, print_result renders a color-coded panel in the server terminal. The border and label color are green for safe content, yellow for spam, and red for hate speech, so the result of each request is readable at a glance without parsing JSON.
_LABEL_COLOR = {"safe": "green", "spam": "yellow", "hate_speech": "red"}
_LABEL_ICON = {"safe": "✓", "spam": "⚠", "hate_speech": "✗"}
def print_result(label, severity, categories, explanation, rewrite, usage, trace_id):
color = _LABEL_COLOR.get(label, "white") # green / yellow / red based on label
icon = _LABEL_ICON.get(label, "?") # ✓ / ⚠ / ✗
lines = [] # start with an empty list of rich-formatted text lines
lines.append( # first line: label icon, name, and optional severity score
f"[bold]Label :[/bold] [{color}]{icon} {label.upper()}[/{color}]" # colored label with checkmark/warning/cross icon
+ (f" [dim](severity {severity}/5)[/dim]" if severity else "") # append severity score only when content is flagged
)
if categories: # skip the categories line entirely for safe content or when the list is empty
lines.append(f"[bold]Categories :[/bold] {', '.join(categories)}") # comma-separated sub-category names
lines.append(f"\n[bold]Explanation:[/bold]\n {explanation}") # indented explanation on its own block
if rewrite: # rewrite is None for safe content — only show when it was generated
lines.append(f"\n[bold]Rewrite :[/bold]\n {rewrite}") # the cleaned version of the flagged text
lines.append( # footer line showing cost and trace ID for this request
f"\n[dim]Tokens: {usage['total_tokens']} · " # total tokens used across all stages
f"Cost: ${usage['total_cost']:.6f} · " # USD cost rounded to 6 decimal places
f"Trace: {trace_id[:16]}...[/dim]" # first 16 chars of the hex trace ID
)
console.print() # blank line before the panel for visual spacing
console.print(Panel( # render all lines inside a rich bordered panel
"\n".join(lines), # join the formatted lines into a single multiline string
title=f"[bold {color}]Moderation Result[/bold {color}]", # colored panel title — green, yellow, or red
border_style=color, # border color matches the label color
padding=(1, 2), # 1 line top/bottom padding, 2 characters left/right padding
))
console.print() # blank line after the panel before the next trace output
The footer line inside the panel shows the total token count, the USD cost for that request, and the first 16 characters of the trace ID. The trace ID lets you cross-reference the result panel with the span output above it and with the matching entry in traces.json.
Saving Stats
save_stats uses a shared helper computeusage to calculate token and cost totals for any list of call records. It calls this helper twice: once on call_log for lifetime totals and once on session_call_log for the current session. It then merges the result into a sessions array in stats.json.
def _compute_usage(entries): # compute per-stage and total token/cost breakdown from a list of call records
def _s(stage, key): return sum(e["result"][key] for e in entries if e["stage"] == stage) # sum one result field for one stage
cls_input = _s("classify", "prompt_tokens"); cls_output = _s("classify", "completion_tokens") # classify input and output token counts
cls_tokens = _s("classify", "total_tokens"); cls_cost = _s("classify", "total_cost") # classify combined tokens and USD cost
exp_input = _s("explain", "prompt_tokens"); exp_output = _s("explain", "completion_tokens") # explain input and output token counts
exp_tokens = _s("explain", "total_tokens"); exp_cost = _s("explain", "total_cost") # explain combined tokens and USD cost
rew_input = _s("rewrite", "prompt_tokens"); rew_output = _s("rewrite", "completion_tokens") # rewrite input and output token counts
rew_tokens = _s("rewrite", "total_tokens"); rew_cost = _s("rewrite", "total_cost") # rewrite combined tokens and USD cost
return {
"classify": {"total_input_tokens": cls_input, "total_output_tokens": cls_output, # classify stage token breakdown
"total_tokens": cls_tokens, "total_cost": round(cls_cost, 6)}, # classify combined total and cost in USD
"explain": {"total_input_tokens": exp_input, "total_output_tokens": exp_output, # explain stage token breakdown
"total_tokens": exp_tokens, "total_cost": round(exp_cost, 6)}, # explain combined total and cost in USD
"rewrite": {"total_input_tokens": rew_input, "total_output_tokens": rew_output, # rewrite stage token breakdown
"total_tokens": rew_tokens, "total_cost": round(rew_cost, 6)}, # rewrite combined total and cost in USD
"total_input_tokens": cls_input + exp_input + rew_input, # grand total input tokens across all three stages
"total_output_tokens": cls_output + exp_output + rew_output, # grand total output tokens across all three stages
"total_tokens": cls_tokens + exp_tokens + rew_tokens, # grand total tokens for this set of entries
"total_cost": round(cls_cost + exp_cost + rew_cost, 6), # grand total USD cost for this set of entries
}
def save_stats(): # write lifetime totals + per-session breakdown to stats.json
if not call_log: # nothing to save if no calls have been made yet
return
try: # load the existing sessions list so we can update the current session entry
with open("stats.json", "r", encoding="utf-8") as f:
sessions = json.load(f).get("sessions", [])
except (FileNotFoundError, json.JSONDecodeError):
sessions = []
current_session = { # entry for the current server run
"session_id": session_id, # ISO timestamp assigned at startup
"total_requests": len(session_request_log), # requests handled in this run only
"total_api_calls": len(session_call_log), # LLM calls made in this run only
"usage": _compute_usage(session_call_log), # token and cost breakdown for this run only
}
for i, s in enumerate(sessions): # replace the existing entry for this session if present
if s["session_id"] == session_id:
sessions[i] = current_session
break
else:
sessions.append(current_session) # first save for this session — append a new entry
output = {
"run_info": { # lifetime totals across all sessions
"model": mod_model, # model used for all calls
"timestamp": datetime.now().isoformat(), # last-updated timestamp
"total_requests": len(request_log), # total /moderate requests ever handled
"total_api_calls": len(call_log), # total LLM calls ever made
"usage": _compute_usage(call_log), # lifetime token and cost breakdown
},
"sessions": sessions, # one entry per server run — shows cost and tokens per session
"requests": request_log, # every /moderate request ever handled
"calls": call_log, # every LLM call ever made
}
with open("stats.json", "w", encoding="utf-8") as f:
json.dump(output, f, indent=2)
The sessions array grows by one entry each time uvicorn restarts. Each entry has its own total_requests, total_api_calls, and per-stage usage breakdown showing exactly what that server run cost. The top-level run_info always reflects the cumulative total across all sessions.
The /moderate Endpoint
The endpoint ties everything together. It opens a root pipeline span, runs all three stages as child spans, computes per-request totals, prints the result panel, and saves stats. All of this happens within a single with tracer.start_as_current_span block.
@app.post("/moderate")
async def moderate(req: ModerateRequest): # FastAPI calls this for every POST /moderate request
start_idx = len(call_log) # mark the start index so we can total only this request's calls
with tracer.start_as_current_span("moderation.pipeline") as pipeline_span: # root pipeline span — parent of all three stage spans
pipeline_span.set_attribute("input.text_length", len(req.text)) # record input size on the pipeline span
# Stage 1 — classify
with tracer.start_as_current_span("moderation.classify") as classify_span: # child span for the classify stage
classification = classify_content(req.text, classify_span) # runs the classify LLM call
# Stage 2 — explain
with tracer.start_as_current_span("moderation.explain") as explain_span: # child span for the explain stage
explanation = explain_classification( # runs the explain LLM call
req.text, classification["label"], explain_span
)
# Stage 3 — rewrite (only when content is flagged)
rewrite = None # default to None for safe content
if classification["label"] != "safe": # skip rewrite stage entirely for safe content
with tracer.start_as_current_span("moderation.rewrite") as rewrite_span: # child span for the rewrite stage
rewrite_result = rewrite_content(req.text, rewrite_span) # runs the rewrite LLM call
rewrite = rewrite_result.get("rewrite") # extract the cleaned text string
# Compute per-request totals from only this request's calls
request_calls = call_log[start_idx:] # slice only the calls made in this request
total_tokens = sum(c["result"]["total_tokens"] for c in request_calls) # sum tokens across all stages
total_cost = sum(c["result"]["total_cost"] for c in request_calls) # sum cost across all stages
pipeline_span.set_attribute("moderation.total_tokens", total_tokens) # record pipeline-level token total
pipeline_span.set_attribute("moderation.total_cost_usd", round(total_cost, 6)) # record pipeline-level cost
ctx = trace.get_current_span().get_span_context() # read the active span context
trace_id = format(ctx.trace_id, "032x") if ctx.is_valid else "n/a" # format as hex string for the response
_req_record = { # build the request record once and share it
"trace_id": trace_id, # hex trace ID linking this record to its OTel trace
"text": req.text, # the original text that was submitted for moderation
"label": classification["label"], # classification decision: "hate_speech", "spam", or "safe"
"severity": classification.get("severity"), # severity score 1–5 or null for safe content
"categories": classification.get("categories", []), # list of triggered sub-categories
"explanation": explanation.get("explanation"), # assessor's reasoning for the label
"rewrite": rewrite, # cleaned text or null if content was safe
"usage": { # per-request token and cost summary
"total_tokens": total_tokens, # tokens used across all stages in this request
"total_cost": round(total_cost, 6), # USD cost for this request
},
}
request_log.append(_req_record) # lifetime log — persisted across restarts
session_request_log.append(_req_record) # current-session log — resets on every restart
print_result( # print a rich panel to the server terminal
classification["label"],
classification.get("severity"),
classification.get("categories", []),
explanation.get("explanation", ""),
rewrite,
{"total_tokens": total_tokens, "total_cost": round(total_cost, 6)},
trace_id,
)
save_stats() # write updated stats.json after every request so data survives an unexpected shutdown
return { # return the full moderation result as JSON
"trace_id": trace_id, # hex trace ID — correlates response with the terminal trace output
"label": classification["label"], # "hate_speech", "spam", or "safe"
"severity": classification.get("severity"), # integer 1–5 or null
"categories": classification.get("categories", []), # list of sub-categories e.g. ["profanity"]
"explanation": explanation.get("explanation"), # one or two sentences explaining the decision
"rewrite": rewrite, # cleaned version of the text, or null if safe
"usage": { # per-request token and cost summary
"total_tokens": total_tokens, # combined tokens across all stages run
"total_cost": round(total_cost, 6), # combined USD cost for this request
},
}
The start_idx pattern isolates per-request cost from the global call_log. Because multiple requests can be in flight concurrently in a FastAPI deployment, slicing from a pre-recorded index is more reliable than tracking a running delta.
Running the API
With all the code in place, start the server in your project directory with the virtual environment active:
uvicorn main:app --reload --port 8081
The server starts and is ready to accept requests:

Send requests using curl from a second terminal:
curl -X POST http://127.0.0.1:8081/moderate -H "Content-Type: application/json" -d "{\"text\": \"I love hiking on weekends. The mountain trails near my city are beautiful.\"}"

curl -X POST http://127.0.0.1:8081/moderate -H "Content-Type: application/json" -d "{\"text\": \"CLICK HERE NOW!!! Win $5000 FREE today. Limited time offer. Act fast!!!\"}"

curl -X POST http://127.0.0.1:8081/moderate -H "Content-Type: application/json" -d "{\"text\": \"People from that country are all criminals and should be banned.\"}"
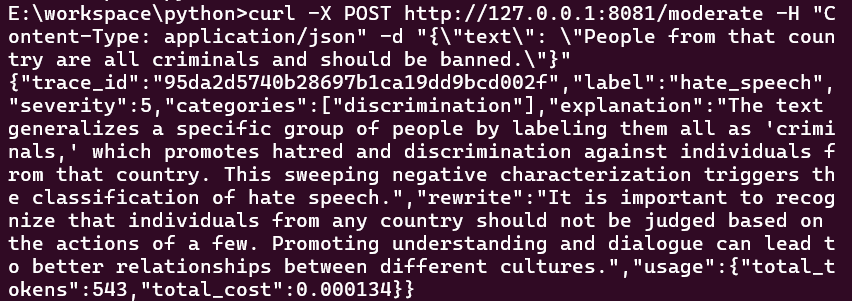
In the server terminal you will see the OpenTelemetry spans printed by PrettySpanExporter, followed by the Rich result panel:







The JSON response is returned to the caller with the same data. After each request, stats.json is updated with the per-session entry and lifetime totals, and every span is appended to traces.json.
stats.json file
{
"run_info": {
"model": "gpt-4o-mini",
"timestamp": "2026-06-19T12:46:26.283223",
"total_requests": 3,
"total_api_calls": 8,
"usage": {
"classify": {
"total_input_tokens": 729,
"total_output_tokens": 74,
"total_tokens": 803,
"total_cost": 0.000154
},
"explain": {
"total_input_tokens": 287,
"total_output_tokens": 147,
"total_tokens": 434,
"total_cost": 0.000131
},
"rewrite": {
"total_input_tokens": 190,
"total_output_tokens": 79,
"total_tokens": 269,
"total_cost": 7.6e-05
},
"total_input_tokens": 1206,
"total_output_tokens": 300,
"total_tokens": 1506,
"total_cost": 0.000361
}
},
"sessions": [
{
"session_id": "2026-06-19T12:45:10.852029",
"total_requests": 3,
"total_api_calls": 8,
"usage": {
"classify": {
"total_input_tokens": 729,
"total_output_tokens": 74,
"total_tokens": 803,
"total_cost": 0.000154
},
"explain": {
"total_input_tokens": 287,
"total_output_tokens": 147,
"total_tokens": 434,
"total_cost": 0.000131
},
"rewrite": {
"total_input_tokens": 190,
"total_output_tokens": 79,
"total_tokens": 269,
"total_cost": 7.6e-05
},
"total_input_tokens": 1206,
"total_output_tokens": 300,
"total_tokens": 1506,
"total_cost": 0.000361
}
}
],
"requests": [
{
"trace_id": "8bd2d81620e44650ccdd8500bc5b74e1",
"text": "I love hiking on weekends. The mountain trails near my city are beautiful.",
"label": "safe",
"severity": null,
"categories": [],
"explanation": "The text expresses a positive sentiment about hiking and describes the beauty of mountain trails, which is a safe and wholesome topic without any harmful or inappropriate content.",
"rewrite": null,
"usage": {
"total_tokens": 396,
"total_cost": 8.5e-05
}
},
{
"trace_id": "1d8c4f9901beb3e116b2d2c257252819",
"text": "CLICK HERE NOW!!! Win $5000 FREE today. Limited time offer. Act fast!!!",
"label": "spam",
"severity": 2,
"categories": [
"promotional",
"urgency"
],
"explanation": "The text contains promotional language and a sense of urgency, such as 'CLICK HERE NOW!!!' and 'Limited time offer,' which are typical characteristics of spam. Additionally, the promise of winning money for free is a common tactic used in spam messages to attract attention.",
"rewrite": "Take advantage of our special promotion for a chance to win $5000! This offer is available for a limited time, so don't miss out!",
"usage": {
"total_tokens": 567,
"total_cost": 0.000141
}
},
{
"trace_id": "95da2d5740b28697b1ca19dd9bcd002f",
"text": "People from that country are all criminals and should be banned.",
"label": "hate_speech",
"severity": 5,
"categories": [
"discrimination"
],
"explanation": "The text generalizes a specific group of people by labeling them all as 'criminals,' which promotes hatred and discrimination against individuals from that country. This sweeping negative characterization triggers the classification of hate speech.",
"rewrite": "It is important to recognize that individuals from any country should not be judged based on the actions of a few. Promoting understanding and dialogue can lead to better relationships between different cultures.",
"usage": {
"total_tokens": 543,
"total_cost": 0.000134
}
}
],
"calls": [
{
"timestamp": "2026-06-19T12:45:20.289731",
"stage": "classify",
"model": "gpt-4o-mini",
"result": {
"prompt_tokens": 243,
"completion_tokens": 20,
"total_tokens": 263,
"input_cost": 3.64e-05,
"output_cost": 1.2e-05,
"total_cost": 4.84e-05
},
"latency_seconds": 2.997
},
{
"timestamp": "2026-06-19T12:45:22.216239",
"stage": "explain",
"model": "gpt-4o-mini",
"result": {
"prompt_tokens": 95,
"completion_tokens": 38,
"total_tokens": 133,
"input_cost": 1.42e-05,
"output_cost": 2.28e-05,
"total_cost": 3.7e-05
},
"latency_seconds": 1.904
},
{
"timestamp": "2026-06-19T12:46:10.243035",
"stage": "classify",
"model": "gpt-4o-mini",
"result": {
"prompt_tokens": 246,
"completion_tokens": 28,
"total_tokens": 274,
"input_cost": 3.69e-05,
"output_cost": 1.68e-05,
"total_cost": 5.37e-05
},
"latency_seconds": 1.075
},
{
"timestamp": "2026-06-19T12:46:12.608421",
"stage": "explain",
"model": "gpt-4o-mini",
"result": {
"prompt_tokens": 98,
"completion_tokens": 61,
"total_tokens": 159,
"input_cost": 1.47e-05,
"output_cost": 3.66e-05,
"total_cost": 5.13e-05
},
"latency_seconds": 2.33
},
{
"timestamp": "2026-06-19T12:46:13.930769",
"stage": "rewrite",
"model": "gpt-4o-mini",
"result": {
"prompt_tokens": 98,
"completion_tokens": 36,
"total_tokens": 134,
"input_cost": 1.47e-05,
"output_cost": 2.16e-05,
"total_cost": 3.63e-05
},
"latency_seconds": 1.293
},
{
"timestamp": "2026-06-19T12:46:23.760319",
"stage": "classify",
"model": "gpt-4o-mini",
"result": {
"prompt_tokens": 240,
"completion_tokens": 26,
"total_tokens": 266,
"input_cost": 3.6e-05,
"output_cost": 1.56e-05,
"total_cost": 5.16e-05
},
"latency_seconds": 1.513
},
{
"timestamp": "2026-06-19T12:46:24.942989",
"stage": "explain",
"model": "gpt-4o-mini",
"result": {
"prompt_tokens": 94,
"completion_tokens": 48,
"total_tokens": 142,
"input_cost": 1.41e-05,
"output_cost": 2.88e-05,
"total_cost": 4.29e-05
},
"latency_seconds": 1.171
},
{
"timestamp": "2026-06-19T12:46:26.269788",
"stage": "rewrite",
"model": "gpt-4o-mini",
"result": {
"prompt_tokens": 92,
"completion_tokens": 43,
"total_tokens": 135,
"input_cost": 1.38e-05,
"output_cost": 2.58e-05,
"total_cost": 3.96e-05
},
"latency_seconds": 1.307
}
]
}
traces.json.
[
{
"trace_id": "8bd2d81620e44650ccdd8500bc5b74e1",
"span_id": "caa248f1ddba5006",
"name": "POST /moderate http receive",
"timestamp": "2026-06-19T12:45:17.291630",
"duration_ms": 0.03,
"attributes": {
"asgi.event.type": "http.request"
}
},
{
"trace_id": "8bd2d81620e44650ccdd8500bc5b74e1",
"span_id": "f43ab5e1ce04a02c",
"name": "moderation.classify",
"timestamp": "2026-06-19T12:45:17.292443",
"duration_ms": 2997.32,
"attributes": {
"input.text_length": 74,
"llm.model": "gpt-4o-mini",
"llm.stage": "classify",
"llm.tokens.input": 243,
"llm.tokens.output": 20,
"llm.tokens.total": 263,
"llm.cost.usd": 4.84e-05,
"llm.latency_seconds": 2.997,
"moderation.label": "safe",
"moderation.severity": 0
}
},
{
"trace_id": "8bd2d81620e44650ccdd8500bc5b74e1",
"span_id": "47c51845b151eb6c",
"name": "moderation.explain",
"timestamp": "2026-06-19T12:45:20.311991",
"duration_ms": 1904.27,
"attributes": {
"moderation.label_explained": "safe",
"llm.model": "gpt-4o-mini",
"llm.stage": "explain",
"llm.tokens.input": 95,
"llm.tokens.output": 38,
"llm.tokens.total": 133,
"llm.cost.usd": 3.7e-05,
"llm.latency_seconds": 1.904
}
},
{
"trace_id": "8bd2d81620e44650ccdd8500bc5b74e1",
"span_id": "068e73d7ec0ee688",
"name": "moderation.pipeline",
"timestamp": "2026-06-19T12:45:17.292412",
"duration_ms": 4949.83,
"attributes": {
"input.text_length": 74,
"moderation.total_tokens": 396,
"moderation.total_cost_usd": 8.5e-05
}
},
{
"trace_id": "8bd2d81620e44650ccdd8500bc5b74e1",
"span_id": "75e13d845376caba",
"name": "POST /moderate http send",
"timestamp": "2026-06-19T12:45:22.252301",
"duration_ms": 0.04,
"attributes": {
"asgi.event.type": "http.response.start",
"http.status_code": 200
}
},
{
"trace_id": "8bd2d81620e44650ccdd8500bc5b74e1",
"span_id": "532485e2a3d60a54",
"name": "POST /moderate http send",
"timestamp": "2026-06-19T12:45:22.260557",
"duration_ms": 0.03,
"attributes": {
"asgi.event.type": "http.response.body"
}
},
{
"trace_id": "8bd2d81620e44650ccdd8500bc5b74e1",
"span_id": "9dd1818828ce657c",
"name": "POST /moderate",
"timestamp": "2026-06-19T12:45:17.290609",
"duration_ms": 4977.21,
"attributes": {
"http.scheme": "http",
"http.host": "127.0.0.1:8081",
"net.host.port": 8081,
"http.flavor": "1.1",
"http.target": "/moderate",
"http.url": "http://127.0.0.1:8081/moderate",
"http.method": "POST",
"http.server_name": "127.0.0.1:8081",
"http.user_agent": "curl/8.19.0",
"net.peer.ip": "127.0.0.1",
"net.peer.port": 63666,
"http.route": "/moderate",
"http.status_code": 200
}
},
{
"trace_id": "1d8c4f9901beb3e116b2d2c257252819",
"span_id": "4ba54400a111ef96",
"name": "POST /moderate http receive",
"timestamp": "2026-06-19T12:46:09.166308",
"duration_ms": 0.03,
"attributes": {
"asgi.event.type": "http.request"
}
},
{
"trace_id": "1d8c4f9901beb3e116b2d2c257252819",
"span_id": "7c1bcea5be270347",
"name": "moderation.classify",
"timestamp": "2026-06-19T12:46:09.167695",
"duration_ms": 1075.38,
"attributes": {
"input.text_length": 71,
"llm.model": "gpt-4o-mini",
"llm.stage": "classify",
"llm.tokens.input": 246,
"llm.tokens.output": 28,
"llm.tokens.total": 274,
"llm.cost.usd": 5.37e-05,
"llm.latency_seconds": 1.075,
"moderation.label": "spam",
"moderation.severity": 2
}
},
{
"trace_id": "1d8c4f9901beb3e116b2d2c257252819",
"span_id": "7dbe302e7ab18c81",
"name": "moderation.explain",
"timestamp": "2026-06-19T12:46:10.277999",
"duration_ms": 2330.45,
"attributes": {
"moderation.label_explained": "spam",
"llm.model": "gpt-4o-mini",
"llm.stage": "explain",
"llm.tokens.input": 98,
"llm.tokens.output": 61,
"llm.tokens.total": 159,
"llm.cost.usd": 5.13e-05,
"llm.latency_seconds": 2.33
}
},
{
"trace_id": "1d8c4f9901beb3e116b2d2c257252819",
"span_id": "d535309edf9d61b0",
"name": "moderation.rewrite",
"timestamp": "2026-06-19T12:46:12.637900",
"duration_ms": 1292.93,
"attributes": {
"llm.model": "gpt-4o-mini",
"llm.stage": "rewrite",
"llm.tokens.input": 98,
"llm.tokens.output": 36,
"llm.tokens.total": 134,
"llm.cost.usd": 3.63e-05,
"llm.latency_seconds": 1.293
}
},
{
"trace_id": "1d8c4f9901beb3e116b2d2c257252819",
"span_id": "1b94c9e77cadee50",
"name": "moderation.pipeline",
"timestamp": "2026-06-19T12:46:09.167658",
"duration_ms": 4785.26,
"attributes": {
"input.text_length": 71,
"moderation.total_tokens": 567,
"moderation.total_cost_usd": 0.000141
}
},
{
"trace_id": "1d8c4f9901beb3e116b2d2c257252819",
"span_id": "7938c9030883323a",
"name": "POST /moderate http send",
"timestamp": "2026-06-19T12:46:13.987421",
"duration_ms": 0.06,
"attributes": {
"asgi.event.type": "http.response.start",
"http.status_code": 200
}
},
{
"trace_id": "1d8c4f9901beb3e116b2d2c257252819",
"span_id": "4fdb268ed83ab8ff",
"name": "POST /moderate http send",
"timestamp": "2026-06-19T12:46:14.023086",
"duration_ms": 0.06,
"attributes": {
"asgi.event.type": "http.response.body"
}
},
{
"trace_id": "1d8c4f9901beb3e116b2d2c257252819",
"span_id": "f8fb26f97a69c4a5",
"name": "POST /moderate",
"timestamp": "2026-06-19T12:46:09.166107",
"duration_ms": 4886.7,
"attributes": {
"http.scheme": "http",
"http.host": "127.0.0.1:8081",
"net.host.port": 8081,
"http.flavor": "1.1",
"http.target": "/moderate",
"http.url": "http://127.0.0.1:8081/moderate",
"http.method": "POST",
"http.server_name": "127.0.0.1:8081",
"http.user_agent": "curl/8.19.0",
"net.peer.ip": "127.0.0.1",
"net.peer.port": 60143,
"http.route": "/moderate",
"http.status_code": 200
}
},
{
"trace_id": "95da2d5740b28697b1ca19dd9bcd002f",
"span_id": "2914ea25973a2935",
"name": "POST /moderate http receive",
"timestamp": "2026-06-19T12:46:22.246203",
"duration_ms": 0.02,
"attributes": {
"asgi.event.type": "http.request"
}
},
{
"trace_id": "95da2d5740b28697b1ca19dd9bcd002f",
"span_id": "cf637d66fbc3f9f5",
"name": "moderation.classify",
"timestamp": "2026-06-19T12:46:22.247397",
"duration_ms": 1512.97,
"attributes": {
"input.text_length": 64,
"llm.model": "gpt-4o-mini",
"llm.stage": "classify",
"llm.tokens.input": 240,
"llm.tokens.output": 26,
"llm.tokens.total": 266,
"llm.cost.usd": 5.16e-05,
"llm.latency_seconds": 1.513,
"moderation.label": "hate_speech",
"moderation.severity": 5
}
},
{
"trace_id": "95da2d5740b28697b1ca19dd9bcd002f",
"span_id": "374edcfebea7102c",
"name": "moderation.explain",
"timestamp": "2026-06-19T12:46:23.771454",
"duration_ms": 1171.57,
"attributes": {
"moderation.label_explained": "hate_speech",
"llm.model": "gpt-4o-mini",
"llm.stage": "explain",
"llm.tokens.input": 94,
"llm.tokens.output": 48,
"llm.tokens.total": 142,
"llm.cost.usd": 4.29e-05,
"llm.latency_seconds": 1.171
}
},
{
"trace_id": "95da2d5740b28697b1ca19dd9bcd002f",
"span_id": "0b03f1f127f68863",
"name": "moderation.rewrite",
"timestamp": "2026-06-19T12:46:24.962636",
"duration_ms": 1307.2,
"attributes": {
"llm.model": "gpt-4o-mini",
"llm.stage": "rewrite",
"llm.tokens.input": 92,
"llm.tokens.output": 43,
"llm.tokens.total": 135,
"llm.cost.usd": 3.96e-05,
"llm.latency_seconds": 1.307
}
},
{
"trace_id": "95da2d5740b28697b1ca19dd9bcd002f",
"span_id": "3e000e3f390fa94e",
"name": "moderation.pipeline",
"timestamp": "2026-06-19T12:46:22.247365",
"duration_ms": 4036.91,
"attributes": {
"input.text_length": 64,
"moderation.total_tokens": 543,
"moderation.total_cost_usd": 0.000134
}
},
{
"trace_id": "95da2d5740b28697b1ca19dd9bcd002f",
"span_id": "96fcb7bcd2036fab",
"name": "POST /moderate http send",
"timestamp": "2026-06-19T12:46:26.300408",
"duration_ms": 0.03,
"attributes": {
"asgi.event.type": "http.response.start",
"http.status_code": 200
}
},
{
"trace_id": "95da2d5740b28697b1ca19dd9bcd002f",
"span_id": "e0906a853e8bfb4a",
"name": "POST /moderate http send",
"timestamp": "2026-06-19T12:46:26.311499",
"duration_ms": 0.02,
"attributes": {
"asgi.event.type": "http.response.body"
}
},
{
"trace_id": "95da2d5740b28697b1ca19dd9bcd002f",
"span_id": "55ec8598b8a32103",
"name": "POST /moderate",
"timestamp": "2026-06-19T12:46:22.246074",
"duration_ms": 4076.31,
"attributes": {
"http.scheme": "http",
"http.host": "127.0.0.1:8081",
"net.host.port": 8081,
"http.flavor": "1.1",
"http.target": "/moderate",
"http.url": "http://127.0.0.1:8081/moderate",
"http.method": "POST",
"http.server_name": "127.0.0.1:8081",
"http.user_agent": "curl/8.19.0",
"net.peer.ip": "127.0.0.1",
"net.peer.port": 64970,
"http.route": "/moderate",
"http.status_code": 200
}
}
]
Who Can Benefit
Students learning applied AI or backend development can use this project to understand how multi-stage LLM pipelines work in practice. Building the classifier, explainer, and rewriter from scratch makes the design decisions concrete in a way that using a ready-made moderation library alone does not.
Startups building user-generated content platforms can use this pattern to moderate posts, comments, and messages at scale without a dedicated moderation team for low-severity content.
Product teams shipping chat or messaging features can integrate the rewrite stage to offer users a one-click option to clean up flagged messages before posting.
Data scientists working on trust and safety can use the traces.json and stats.json files to analyze moderation patterns over time, including which categories appear most frequently, which inputs have the highest cost, and where the pipeline is slowest.
AI engineers can extend the pipeline with additional stages: a fourth stage to detect personally identifiable information, or a routing stage that escalates high-severity content to a stronger model.
Enterprises can adapt this pattern to domain-specific moderation: financial advice detection, medical content warnings, or regulatory compliance checks that require a written audit trail for every decision.
How Codersarts Can Help
If you want to take this further, Codersarts offers hands-on support at every stage.
For learners: Live 1-to-1 sessions with an AI engineer who can walk through the pipeline architecture, prompt design, and OpenTelemetry instrumentation in detail.
For teams: End-to-end development of custom content moderation systems including multi-class classifiers, human-in-the-loop escalation workflows, and dashboard integrations.
For enterprises: Architecture consulting for production-grade moderation pipelines including latency optimization, cost controls, audit logging, and compliance documentation.
Reach out at contact@codersarts.com or visit www.codersarts.com to get started.
Continue Your AI Learning Journey with Codersarts
If you enjoyed this article and would like to discover more about modern AI applications, production-ready LLM systems, and real-world RAG and MCP implementations, be sure to explore these other blogs from Codersarts:
Build a Cost-Efficient Writing Quality Checker with Tiered Model Routing and OpenAI
Build Your First A2A Agent: An Email Drafting Pipeline Using Python and OpenAI
Building an AI Interview Prep Agent with Qwen 3.7 Max and Streamlit
https://www.codersarts.com/post/building-an-ai-interview-prep-agent-with-qwen-3-7-max-and-streamlit
Building an AI Book Recommender with Kimi K2 and Streamlit
https://www.codersarts.com/post/building-an-ai-book-recommender-with-kimi-k2-and-streamlit




Comments