Build Your First A2A Agent: An Email Drafting Pipeline Using Python and OpenAI
- Jun 11
- 21 min read
Introduction
Most AI email tools work as a single prompt: paste your draft, get a rewrite. The problem is that rewriting well requires two very different cognitive tasks — understanding what is wrong with the email, and then knowing how to fix it. Combining both into one prompt produces mediocre results for the same reason that asking a single person to be both a critic and a writer at the same time produces weak output.
In this tutorial, we build an A2A Multi-Agent Email Drafting Pipeline where those two tasks are handled by two independent, specialised agents that communicate over HTTP using the Agent-to-Agent (A2A) protocol. Agent 1 classifies the email — intent, tone, recipient type, and specific issues. Agent 2 receives that classification alongside the original draft and rewrites the email professionally, fixing every identified problem.
The key concept here is horizontal agent communication: neither agent knows about the other’s internals. They expose standard A2A interfaces, discover each other via agent cards, and exchange typed messages — the same pattern used in production multi-agent systems.

What We’re Building
The pipeline follows a two-step sequential workflow:
Step | Agent | What Happens |
1 | Classifier Agent (port 8001) | Reads the raw draft, returns intent, tone, recipient type, and a list of specific issues |
2 | Rewriter Agent (port 8002) | Receives the original draft plus the classification, returns a subject line, professional body, and list of improvements |
The steps are sequential by design — Step 2 depends on Step 1’s output. The rewriter cannot fix issues it has not identified, so both pieces of context (original email and classification) are combined into the rewriter’s input.
The entry point is a terminal app where the user pastes a rough draft, and the pipeline returns the full classification, the rewritten email, and a token-level cost breakdown.
What is the A2A Protocol?
A2A (Agent-to-Agent) is an open protocol for horizontal communication between independent agents. Unlike tool calls (where an LLM calls a function within the same process), A2A agents run as separate HTTP services and communicate through a standardised message format.
Each agent exposes: - An agent card at /.well-known/agent-card.json — a JSON description of its capabilities, input/output formats, and skills - A message endpoint that accepts SendMessageRequest objects and returns a Task result.
The orchestrator discovers agents by fetching their agent card URL, then sends messages using the A2A client. Agents never call each other directly — all routing goes through the orchestrator.
This design means each agent can be developed, tested, and deployed independently. Swapping the rewriter agent for a different implementation requires no changes to the classifier or orchestrator.
Tech Stack
Component | Tool |
Agent Protocol | A2A SDK (a2a-sdk==0.3.26) |
AI Model | GPT-4o-mini (both agents) |
API Client | openai Python SDK |
HTTP Server | Uvicorn + Starlette (via A2A SDK) |
HTTP Client | httpx (async) |
Terminal UI | rich |
Env Management | python-dotenv |
Why pin a2a-sdk==0.3.26? The SDK’s API changed significantly between minor versions. v0.3.26 uses Pydantic models (A2AClient, SendMessageRequest, Part(root=TextPart(...))) while later versions switched to a protobuf-based API. Pinning ensures the code runs reliably.
Project Structure
a2a_email_pipeline/
├── classifier_agent/
│ ├── __init__.py
│ ├── executor.py # ClassifierExecutor — OpenAI call + A2A response
│ └── server.py # Agent card + Starlette server on port 8001
├── rewriter_agent/
│ ├── __init__.py
│ ├── executor.py # RewriterExecutor — OpenAI call + A2A response
│ └── server.py # Agent card + Starlette server on port 8002
├── orchestrator.py # EmailOrchestrator — coordinates both agents sequentially
├── app.py # Terminal entry point — launches agents, runs input loop
├── requirements.txt
└── .env
Setting Up
1. Install Dependencies
pip install "a2a-sdk[http-server]==0.3.26" openai python-dotenv rich httpx uvicorn
2. Configure Environment
Create a .env file in the project folder:
# OpenAI API key — get yours at https://platform.openai.com/api-keys
OPENAI_API_KEY=your_openai_api_key_here
# Model used by the Email Classifier Agent (default: gpt-4o-mini)
CLASSIFIER_MODEL=gpt-4o-mini
# Model used by the Email Rewriter Agent (default: gpt-4o-mini)
REWRITER_MODEL=gpt-4o-mini
# Port for the Email Classifier Agent
CLASSIFIER_AGENT_PORT=8001
# Port for the Email Rewriter Agent
REWRITER_AGENT_PORT=8002
Building the Classifier Agent
The classifier agent is responsible for one thing: reading a raw email draft and returning a structured JSON analysis. It has no knowledge of the rewriter.
Executor — classifier_agent/executor.py
The executor is the brain of the agent. It implements the AgentExecutor interface required by the A2A SDK — two methods, execute() and cancel().
import json # standard library — parses the OpenAI JSON response and serialises the result dict
import os # reads OPENAI_API_KEY and CLASSIFIER_MODEL from the environment after load_dotenv()
from uuid import uuid4 # generates unique IDs for A2A messages and events — required by the protocol
from openai import AsyncOpenAI # async OpenAI client — needed because the executor runs inside an async event loop
from a2a.server.agent_execution import AgentExecutor, RequestContext # AgentExecutor is the interface all A2A executors must implement; RequestContext carries the incoming message
from a2a.server.events import EventQueue # the queue the executor writes results into — the server reads from it to build the HTTP response
from a2a.types import (
TaskStatusUpdateEvent, TaskState, TaskStatus, # used to signal task completion or cancellation back to the A2A framework
Message, Role, Part, TextPart, # A2A message building blocks — TextPart holds the text payload inside a Part inside a Message
)
from dotenv import load_dotenv # reads .env and injects values into os.environ — must be imported before calling load_dotenv()
load_dotenv() # must be called before any os.getenv() — injects .env values into the process environment
_CALL_METADATA = {
"dev_name": "Ganesh", # identifies who made the API call — attached to every OpenAI request for dashboard tracking
"project": "codex-test", # project label for grouping calls in the OpenAI usage dashboard
"environment": "local", # marks calls as coming from a local dev machine — not production
"purpose": "testing", # intent label — useful when reviewing API usage logs
}
# Analyses the raw email and returns intent, tone, recipient type, and specific issues
_CLASSIFY_PROMPT = (
"You are an email tone and intent classifier. "
"Analyse the given email draft and return ONLY JSON: "
'{"intent": "request|complaint|follow-up|introduction|apology|announcement", '
'"tone": "too casual|aggressive|too wordy|unprofessional|appropriate", '
'"recipient_type": "colleague|client|manager|stranger", '
'"issues": ["list of specific tone, grammar, or clarity problems found in the email"]}.'
)
The prompt constrains the model to return only the JSON structure — no markdown, no explanation. response_format={"type": "json_object"} enforces this at the API level.
class ClassifierExecutor(AgentExecutor):
"""A2A executor — reads the raw email draft and classifies its intent, tone, and issues."""
def __init__(self):
self.llm = AsyncOpenAI(api_key=os.getenv("OPENAI_API_KEY", "")) # async client — the executor runs inside an async event loop
self.model = os.getenv("CLASSIFIER_MODEL", "gpt-4o-mini") # read from .env — change the model without touching source code
async def execute(self, context: RequestContext, event_queue: EventQueue) -> None:
raw_email = context.get_user_input() # SDK utility — extracts and joins all text parts from the incoming A2A message
if not raw_email: # guard against empty messages — sends an error result rather than calling the API with nothing
await self._complete(event_queue, context, {"error": "No email text received"})
return
try:
response = await self.llm.chat.completions.create(
model=self.model, # resolved from CLASSIFIER_MODEL in .env — gpt-4o-mini by default
messages=[
{"role": "system", "content": _CLASSIFY_PROMPT}, # sets the model's persona and output format for this call
{"role": "user", "content": f"Email draft:\n{raw_email}"}, # the actual email text the user submitted
],
response_format={"type": "json_object"}, # forces the model to return valid JSON — no markdown fence, no explanation text
max_tokens=250, # classification output is short — 250 tokens is more than enough for the JSON response
metadata=_CALL_METADATA, # attached to the API call for dashboard tracking — does not affect model output
)
raw = response.choices[0].message.content or "{}" # choices[0] is the first completion — or "{}" guards against a None content field
result = json.loads(raw) # parse the JSON string into a Python dict — the prompt guarantees it is valid JSON
# Token counts are passed back so the orchestrator can aggregate cost across both agents
result["prompt_tokens"] = response.usage.prompt_tokens # number of tokens in the system + user messages
result["completion_tokens"] = response.usage.completion_tokens # number of tokens in the model's response
except Exception as exc:
result = {"error": str(exc), "prompt_tokens": 0, "completion_tokens": 0} # on any failure, return a safe error dict with zero token counts
await self._complete(event_queue, context, result) # enqueue the result as a completed task event — the server sends this back to the orchestrator
async def cancel(self, context: RequestContext, event_queue: EventQueue) -> None:
await event_queue.enqueue_event(
TaskStatusUpdateEvent(
context_id=context.context_id or str(uuid4()), # context_id is required — fall back to a new UUID if the context has none
task_id=context.task_id or str(uuid4()), # task_id is required — fall back to a new UUID if the task has none
status=TaskStatus(state=TaskState.canceled), # signals the task was cancelled rather than completed
final=True, # no more events will follow for this task
)
)
async def _complete(self, event_queue: EventQueue, context: RequestContext, result: dict) -> None:
"""Wrap result in an A2A completed-task event and enqueue it."""
msg = Message(
message_id=str(uuid4()), # required by the A2A spec — every message must have a unique sender-generated ID
role=Role.agent, # Role.agent marks this as the agent's reply — the orchestrator looks for agent-role messages
parts=[Part(root=TextPart(text=json.dumps(result)))], # serialise the result dict to a JSON string — the orchestrator will parse it back out
)
await event_queue.enqueue_event(
TaskStatusUpdateEvent(
context_id=context.context_id or str(uuid4()), # required field — identifies the conversation context this task belongs to
task_id=context.task_id or str(uuid4()), # required field — identifies the specific task being completed
status=TaskStatus(state=TaskState.completed, message=msg), # completed state + the message carrying the result JSON
final=True, # marks this as the last event — tells the server the task is done and the response can be sent
)
)
Three things worth noting here:
context.get_user_input() — the A2A SDK provides this utility to extract all text from the incoming message’s parts. This is preferred over manually walking context.message.parts.
context_id and task_id on TaskStatusUpdateEvent — both are required fields in this SDK version. Omitting either causes a Pydantic ValidationError that the server swallows silently, returning an empty response to the orchestrator.
Token counts in the result dict — the executor appends prompt_tokens and completion_tokens to the JSON result so the orchestrator can aggregate them across both agents for the cost display.
Server — classifier_agent/server.py
The server wraps the executor in an A2A-compliant HTTP application. It defines an agent card that describes the agent’s capabilities — this card is served at /.well-known/agent-card.json and is how the orchestrator discovers the agent.
import os # reads CLASSIFIER_AGENT_PORT from the environment after load_dotenv()
import uvicorn # ASGI server — runs the Starlette app built by A2AStarletteApplication
from dotenv import load_dotenv # reads .env so os.getenv can access CLASSIFIER_AGENT_PORT
from a2a.types import AgentCard, AgentCapabilities, AgentSkill # A2A types that describe the agent's identity and capabilities
from a2a.server.apps import A2AStarletteApplication # builds the ASGI app — handles A2A routing, agent card serving, and message dispatch
from a2a.server.request_handlers import DefaultRequestHandler # wires the executor and task store together — handles the full request lifecycle
from a2a.server.tasks import InMemoryTaskStore # stores task state in memory — sufficient for dev since tasks are short-lived
from classifier_agent.executor import ClassifierExecutor # the executor class that does the actual classification work
load_dotenv() # loads .env before reading the port — must be called before os.getenv
_PORT = int(os.getenv("CLASSIFIER_AGENT_PORT", "8001")) # port read from .env — defaults to 8001; int() converts the string env value to an integer
# Describes this agent's capability — read by the orchestrator via agent card discovery
classify_skill = AgentSkill(
id="email_classification", # unique identifier for this skill — used in agent card discovery
name="Email Intent and Tone Classifier", # human-readable name — shown in agent discovery tools
description="Classifies a draft email's intent, tone, recipient type, and lists specific issues", # what the skill does — helps orchestrators choose the right agent
tags=["email", "classification", "tone", "intent"], # searchable tags — help orchestrators find agents by capability keyword
examples=[
"hey can u send me that file asap??", # example of too-casual tone — illustrates the kind of input this agent handles
"i am writing to you because your service was absolutely terrible", # example of aggressive tone
],
inputModes=["text/plain"], # this agent accepts plain text — the orchestrator sends raw email drafts
outputModes=["application/json"], # this agent returns structured JSON — intent, tone, recipient_type, issues
)
# Agent card is served at /.well-known/agent-card.json for A2A discovery
classifier_card = AgentCard(
name="Email Classifier Agent", # display name — shown in A2A discovery tools and dashboards
description="Specialised A2A agent that classifies email drafts by intent, tone, and recipient type",
url=f"http://localhost:{_PORT}/", # base URL where this agent is reachable — the orchestrator uses this to send messages
version="1.0.0", # semantic version — increment when the agent's interface changes
capabilities=AgentCapabilities(streaming=False), # streaming=False — this agent returns a single complete response, not a stream
defaultInputModes=["text/plain"], # default input format — plain text email drafts
defaultOutputModes=["application/json"], # default output format — structured JSON classification result
skills=[classify_skill], # list of skills this agent can perform — orchestrators read these during discovery
)
_cls_handler = DefaultRequestHandler(
agent_executor=ClassifierExecutor(), # the executor instance that handles each incoming A2A request
task_store=InMemoryTaskStore(), # stores task state in memory — fine for dev since tasks complete quickly
)
app = A2AStarletteApplication(
agent_card=classifier_card, # the agent card is served at /.well-known/agent-card.json — this is how the orchestrator discovers this agent
http_handler=_cls_handler, # the request handler that routes incoming messages to the executor
)
if __name__ == "__main__":
uvicorn.run(app.build(), host="0.0.0.0", port=_PORT, log_level="warning") # app.build() returns the ASGI callable; 0.0.0.0 binds to all interfaces; warning suppresses access logs
DefaultRequestHandler wires together the executor and the task store — it handles incoming A2A requests, routes them to ClassifierExecutor.execute(), and manages task lifecycle. InMemoryTaskStore stores task state in memory, which is fine for development since tasks are short-lived.
Building the Rewriter Agent
The rewriter agent receives two pieces of input from the orchestrator: the original email and the classification produced by the classifier. It combines them into a structured rewrite.
Executor — rewriter_agent/executor.py
The structure mirrors the classifier executor. The key difference is the prompt — the rewriter is told not to use generic openers and to fix the specific issues identified in the classification.
# Receives original email + classification context and produces a professional rewrite
_REWRITE_PROMPT = (
"You are a professional email writing assistant. "
"You will receive an original draft email along with its classification (intent, tone, issues). "
"Rewrite the email professionally, fixing all identified issues while preserving the original message. "
"Do NOT use filler openers like 'I hope this message finds you well' or 'I hope you are doing well'. " # explicit prohibition — without this the model defaults to this cliché opener on almost every rewrite
"Get straight to the point after the greeting. "
"Return ONLY JSON: "
'{"subject": "suggested email subject line", '
'"body": "the professionally rewritten email body", '
'"improvements": ["list of specific improvements made to the email"]}.'
)
class RewriterExecutor(AgentExecutor):
"""A2A executor — receives original email + classification, returns a professional rewrite."""
def __init__(self):
self.llm = AsyncOpenAI(api_key=os.getenv("OPENAI_API_KEY", "")) # async client — required because the executor runs inside an async event loop
self.model = os.getenv("REWRITER_MODEL", "gpt-4o-mini") # read from .env — upgrade to gpt-4o here without touching any other code
async def execute(self, context: RequestContext, event_queue: EventQueue) -> None:
# The orchestrator sends the original email + classification as a single combined message
combined_input = context.get_user_input() # SDK utility — extracts and joins all text parts; returns the full combined string
if not combined_input: # guard — sends an error result rather than calling the API with an empty input
await self._complete(event_queue, context, {"error": "No input received"})
return
try:
response = await self.llm.chat.completions.create(
model=self.model, # resolved from REWRITER_MODEL in .env
messages=[
{"role": "system", "content": _REWRITE_PROMPT}, # sets the rewriter persona and enforces the JSON output format
{"role": "user", "content": combined_input}, # the combined original email + classification string from the orchestrator
],
response_format={"type": "json_object"}, # forces valid JSON output — no prose, no markdown, no explanation
max_tokens=500, # rewrites can be longer than the original — 500 allows a full professional email body
metadata=_CALL_METADATA, # attached for dashboard tracking — does not affect model output
)
raw = response.choices[0].message.content or "{}" # choices[0] is the first completion — or "{}" guards against a None content field
result = json.loads(raw) # parse the JSON string returned by the model into a Python dict
result["prompt_tokens"] = response.usage.prompt_tokens # token count for the combined input (original email + classification)
result["completion_tokens"] = response.usage.completion_tokens # token count for the rewritten email response
except Exception as exc:
result = {"error": str(exc), "prompt_tokens": 0, "completion_tokens": 0} # safe fallback — zero token counts so cost stays at $0
await self._complete(event_queue, context, result) # enqueue the result as a completed task event
The rewriter server (rewriter_agent/server.py) follows the same pattern as the classifier server — same imports, same structure, different port (8002), different skill and card definitions.
Building the Orchestrator — orchestrator.py
The orchestrator is the only component that knows both agents exist. It coordinates the two-step pipeline, constructs the combined input for the rewriter, aggregates token counts, and saves stats.
Agent Communication
import json # parses the JSON text extracted from A2A response parts
import time # measures total pipeline elapsed time from start to finish
from datetime import datetime # generates ISO 8601 timestamps for stats records
from pathlib import Path # creates the stats/ directory and constructs the output file path
from uuid import uuid4 # generates unique IDs for A2A request and message objects — required by the protocol
import httpx # async HTTP client — used to make requests to both agent servers
from a2a.client import A2AClient # A2A client — sends SendMessageRequest objects to agents and returns SendMessageResponse
from a2a.types import (
MessageSendParams, SendMessageRequest, # envelope types that wrap the outgoing message for A2A transport
Message, Role, Part, TextPart, # A2A message building blocks — TextPart holds the text inside Part inside Message
)
_PRICING = {"input": 0.150, "output": 0.600} # GPT-4o-mini rates per 1M tokens — used to calculate cost per pipeline run
AGENT_URLS = {
"classifier": "http://localhost:8001/", # URL of the classifier agent — classifies intent, tone, recipient type
"rewriter": "http://localhost:8002/", # URL of the rewriter agent — rewrites the email professionally
}
Saving Stats
STATS_DIR = Path("stats") # directory where all run records are stored
STATS_DIR.mkdir(exist_ok=True) # create stats/ if it does not exist — exist_ok=True prevents an error on subsequent runs
def save_stats(record: dict) -> None:
"""Append one pipeline record to stats/total_summary.json."""
path = STATS_DIR / "total_summary.json" # single file accumulates all pipeline runs — each run is one entry in the JSON array
history = []
if path.exists():
with open(path, encoding="utf-8") as f:
try:
history = json.load(f) # load the existing records — starts empty on the first run
except json.JSONDecodeError:
history = [] # if the file is corrupted or empty, start fresh rather than crashing
history.append(record) # add the new record to the end of the list
with open(path, "w", encoding="utf-8") as f:
json.dump(history, f, indent=2, ensure_ascii=False) # write the full list back — indent=2 keeps the file human-readable
Wrapping and Unwrapping Messages
def _make_request(text: str) -> SendMessageRequest:
"""Wrap plain text in an A2A SendMessageRequest with a unique ID."""
return SendMessageRequest(
id=str(uuid4()), # JSON-RPC request ID — unique per call; used for request/response correlation
params=MessageSendParams(
message=Message(
message_id=str(uuid4()), # required by the A2A spec — every message must carry a unique sender-generated ID
role=Role.user, # Role.user marks this as a message from the client (orchestrator) to the agent
parts=[Part(root=TextPart(text=text))], # TextPart carries the plain text payload; Part wraps it as a discriminated union type
)
),
)
def _extract_result(response) -> dict:
"""Pull the JSON result dict out of an A2A agent response."""
try:
task = response.root.result # response.root is SendMessageSuccessResponse; .result is Task | Message
if hasattr(task, "status") and task.status.message: # task.status.message is the Message the executor placed in TaskStatus
for part in task.status.message.parts: # walk the parts — there is exactly one TextPart in our executors
if hasattr(part.root, "text"): # check that this part is a TextPart (not FilePart or DataPart)
return json.loads(part.root.text) # parse the JSON string the executor serialised into the TextPart
except Exception:
pass # swallow any structural error — returns {} below so the orchestrator can handle missing data gracefully
return {}
The Combined Input
The most important design decision in the orchestrator is how it formats the rewriter’s input. Rather than sending just the classification JSON, it combines both the original email and the classification into a single readable message:
def _build_rewriter_input(raw_email: str, classification: dict) -> str:
"""
Combine the original email and its classification into a single message
for the rewriter agent so it has full context for the rewrite.
"""
issues_text = "; ".join(classification.get("issues", [])) or "none identified" # join multiple issues into one line; fall back to "none identified" if the list is empty
return (
f"Original email:\n{raw_email}\n\n" # include the full original draft so the rewriter stays faithful to the message's intent
f"Classification:\n"
f"- Intent : {classification.get('intent', 'unknown')}\n" # intent tells the rewriter what the email is trying to accomplish
f"- Tone : {classification.get('tone', 'unknown')}\n" # tone tells the rewriter what the main register problem is
f"- Recipient : {classification.get('recipient_type', 'unknown')}\n" # recipient type influences the level of formality in the rewrite
f"- Issues found : {issues_text}\n\n" # specific issues the rewriter must address — passed as plain text, not raw JSON
"Rewrite this email professionally, fixing all identified issues." # explicit closing instruction ties all the context together
)
This combined message is important for two reasons. First, the rewriter needs the original email to produce a faithful rewrite — not just a generic professional email in the same category. Second, making the classification explicit in plain text (rather than passing raw JSON) keeps the rewriter’s system prompt simple.
Sequential Execution
class EmailOrchestrator:
"""
Coordinates the two-step email pipeline using the A2A protocol.
Step 1 — Classifier Agent: reads the raw email, returns intent/tone/issues.
Step 2 — Rewriter Agent: receives original email + classification context,
returns a polished subject line, body, and improvement list.
The two steps are sequential — Step 2 depends on Step 1's output.
"""
async def process_email(self, raw_email: str) -> dict:
start_time = time.time() # capture start time before any network calls — used to compute total elapsed time at the end
async with httpx.AsyncClient() as http: # single shared httpx client for both agent calls — closed automatically when the block exits
# ── Step 1: classify ──────────────────────────────────────────────────────
classifier_client = A2AClient(http, url=AGENT_URLS["classifier"]) # A2AClient takes the httpx client + the agent's base URL — no async factory method in this SDK version
cls_response = await classifier_client.send_message(_make_request(raw_email)) # send the raw email to the classifier and wait for the Task response
classification = _extract_result(cls_response) # pull the intent/tone/issues dict from the Task.status.message.parts
# ── Step 2: rewrite (uses Step 1's output) ────────────────────────────────
rewriter_client = A2AClient(http, url=AGENT_URLS["rewriter"]) # new A2AClient pointing at the rewriter — same httpx client, different URL
rewriter_input = _build_rewriter_input(raw_email, classification) # combine original email + classification into one readable message string
rw_response = await rewriter_client.send_message(_make_request(rewriter_input)) # send the combined context to the rewriter and wait for the Task response
rewrite = _extract_result(rw_response) # pull the subject, body, improvements dict from the response
elapsed = round(time.time() - start_time, 2) # total pipeline time in seconds — includes both network round-trips
# pop() removes the token fields from the classification/rewrite dicts so they do not appear in the output display
total_prompt = classification.pop("prompt_tokens", 0) + rewrite.pop("prompt_tokens", 0) # sum prompt tokens from both agents
total_completion = classification.pop("completion_tokens", 0) + rewrite.pop("completion_tokens", 0) # sum completion tokens from both agents
input_cost = round((total_prompt / 1_000_000) * _PRICING["input"], 6) # GPT-4o-mini input rate is $0.150 per 1M tokens
output_cost = round((total_completion / 1_000_000) * _PRICING["output"], 6) # GPT-4o-mini output rate is $0.600 per 1M tokens
stats_record = {
"timestamp": datetime.now().isoformat(), # ISO 8601 timestamp — used to order records in total_summary.json
"raw_email": raw_email, # the original input — stored so each record is self-contained
"classification": classification, # intent, tone, recipient_type, issues (token fields already removed by pop)
"rewrite": rewrite, # subject, body, improvements (token fields already removed by pop)
"prompt_tokens": total_prompt, # combined prompt tokens from both agents
"completion_tokens": total_completion, # combined completion tokens from both agents
"total_tokens": total_prompt + total_completion, # grand total for the run
"input_cost": input_cost, # cost of the input tokens in USD
"output_cost": output_cost, # cost of the output tokens in USD
"total_cost": round(input_cost + output_cost, 6), # combined cost rounded to 6 decimal places
"total_time_seconds": elapsed, # wall-clock time for the full pipeline run
}
save_stats(stats_record) # append this record to stats/total_summary.json — builds up a history of all pipeline runs
return {
"classification": classification, # displayed in the Classification section of the terminal output
"rewrite": rewrite, # displayed in the Rewritten Email section
"stats": stats_record, # displayed in the Stats section and also written to disk
}
Token counts are pop-ped out of the classification and rewrite dicts before returning — they are aggregated into stats_record and removed from the per-agent dicts so they do not appear in the display.
Building the Terminal App — app.py
The entry point launches both agent servers as subprocesses, waits for them to bind, then runs the input loop.
Imports and Styles
import asyncio # runs the async run_loop() from synchronous main() using asyncio.run()
import subprocess # launches both agent servers as background child processes
import sys # provides sys.executable — the same Python interpreter that is running app.py
import time # used for time.sleep(3) to wait for uvicorn to bind before the first request
from dotenv import load_dotenv # loads .env so OPENAI_API_KEY is available in the subprocesses' inherited environment
from rich.console import Console # rich console — renders coloured text, rules, and panels in the terminal
from rich.panel import Panel # renders the rewritten email body inside a bordered box
from orchestrator import EmailOrchestrator # the orchestrator class that runs the two-agent pipeline
load_dotenv() # must be called before subprocesses are launched — they inherit the already-loaded environment variables
console = Console() # single Console instance shared across all display functions
orchestrator = EmailOrchestrator() # single orchestrator instance reused for every email in the session
INTENT_STYLE = {
"request": "bold cyan", # requests are neutral — cyan is informational without urgency
"complaint": "bold red", # complaints carry urgency — red signals attention needed
"follow-up": "bold yellow", # follow-ups are moderately important — yellow is a mild alert
"introduction": "bold green", # introductions are positive — green signals a new connection
"apology": "bold magenta", # apologies are sensitive — magenta distinguishes them visually
"announcement": "bold blue", # announcements are informational — blue is calm and factual
}
TONE_STYLE = {
"too casual": "yellow", # casual tone needs attention but is not severe — yellow warns without alarming
"aggressive": "bold red", # aggressive tone is the most serious issue — bold red makes it immediately visible
"too wordy": "yellow", # wordy tone is a quality issue — same visual weight as too casual
"unprofessional": "red", # unprofessional tone is concerning — red without bold is slightly less severe than aggressive
"appropriate": "green", # appropriate tone is the ideal outcome — green confirms no issues detected
}
Launching Agent Servers
def launch_agents() -> list:
"""Start classifier and rewriter agent servers as background subprocesses."""
procs = [
subprocess.Popen(
[sys.executable, "-m", "classifier_agent.server"], # sys.executable uses the same venv Python — critical so package imports resolve correctly
stdout=subprocess.DEVNULL, # suppress uvicorn's startup output — keeps the terminal clean
stderr=subprocess.DEVNULL, # suppress server error output — agent errors surface in the orchestrator's exception messages instead
),
subprocess.Popen(
[sys.executable, "-m", "rewriter_agent.server"], # -m flag runs the module — required for correct package-relative imports
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL,
),
]
return procs # returned so main() can terminate both processes on exit
Main Function
def main():
console.print(" [dim]Starting agent servers...[/dim]")
procs = launch_agents() # start both agent servers as background subprocesses
time.sleep(3) # wait for uvicorn to bind to its ports — without this the first request arrives before the server is ready
try:
asyncio.run(run_loop()) # run the async input loop in the main thread — blocks until the user types exit or quit
finally:
for proc in procs:
proc.terminate() # terminate both agent subprocesses — runs even if an exception or KeyboardInterrupt occurs
console.print(" [dim]Agent servers stopped.[/dim]")
The Input Loop
async def run_loop():
print_header() # prints the pipeline title and agent port info
console.print(" Type or paste your rough email draft and press Enter.")
console.print(" Type [bold]exit[/bold] or [bold]quit[/bold] to stop.\n")
while True:
try:
text = input(" Draft: ").strip() # .strip() removes leading/trailing whitespace before processing
except (KeyboardInterrupt, EOFError):
console.print("\n Goodbye.")
break # Ctrl+C or piped input ending — exit cleanly
if not text:
continue # ignore empty input — loop back to the prompt
if text.lower() in ("exit", "quit"):
console.print(" Goodbye.")
break # user typed exit or quit — stop the loop
console.print("\n [dim]Classifying email...[/dim]") # shown immediately so the user sees activity during the ~7s pipeline run
try:
result = await orchestrator.process_email(text) # run both agents sequentially and wait for the combined result
except Exception as exc:
console.print(f" [red]Error: {exc}[/red]")
continue # on error, skip the display and loop back to the prompt
print_result(result) # render classification, rewritten email, and stats to the terminal
console.rule()
console.print()
Display
The print_result function renders classification and rewrite output with colour-coded fields. Intent is shown in uppercase, tone and recipient type in title case — values come directly from the LLM’s JSON output, so .upper() and .title() are applied at display time:
def print_result(result: dict):
classification = result.get("classification", {})
rewrite = result.get("rewrite", {})
stats = result.get("stats", {})
intent = classification.get("intent", "unknown") # one of: request, complaint, follow-up, introduction, apology, announcement
tone = classification.get("tone", "unknown") # one of: too casual, aggressive, too wordy, unprofessional, appropriate
rcpt = classification.get("recipient_type", "unknown") # one of: colleague, client, manager, stranger
issues = classification.get("issues", []) # list of specific problems found — may be empty if tone is appropriate
subject = rewrite.get("subject", "") # suggested email subject line from the rewriter
body = rewrite.get("body", "") # professionally rewritten email body
imprvmts = rewrite.get("improvements", []) # list of changes made — explains what the rewriter fixed and why
intent_style = INTENT_STYLE.get(intent, "white") # look up the rich style for this intent — fall back to white for unexpected values
tone_style = TONE_STYLE.get(tone, "white") # look up the rich style for this tone — fall back to white for unexpected values
console.print(f" Intent : [{intent_style}]{intent.upper()}[/{intent_style}]") # uppercase intent — bolder and more scannable
console.print(f" Tone : [{tone_style}]{tone.title()}[/{tone_style}]") # title case — "too casual" becomes "Too Casual"
console.print(f" Recipient type : {rcpt.title()}") # title case — "colleague" becomes "Colleague"
if issues:
console.print("\n [bold]Issues found:[/bold]")
for issue in issues:
console.print(f" [red]x[/red] {issue}") # red x bullet — visually marks each problem found
if body:
console.print(Panel(
body,
title="[bold]Professional Rewrite[/bold]",
border_style="green", # green border — signals positive output, visually distinct from the red issue markers above
padding=(1, 2), # one line of vertical padding, two chars of horizontal — keeps text away from the border
))
if imprvmts:
console.print("\n [bold]Improvements made:[/bold]")
for item in imprvmts:
console.print(f" [green]✓[/green] {item}") # green checkmark bullet — mirrors the red x above to show resolution
Running the Pipeline
python app.py
The terminal prints:
Starting agent servers...
────── Email Drafting Pipeline — A2A Multi-Agent ──────
Classifier Agent (port 8001) · Rewriter Agent (port 8002)
Type or paste your rough email draft and press Enter.
Type exit or quit to stop.
Draft:
Output and What to Expect
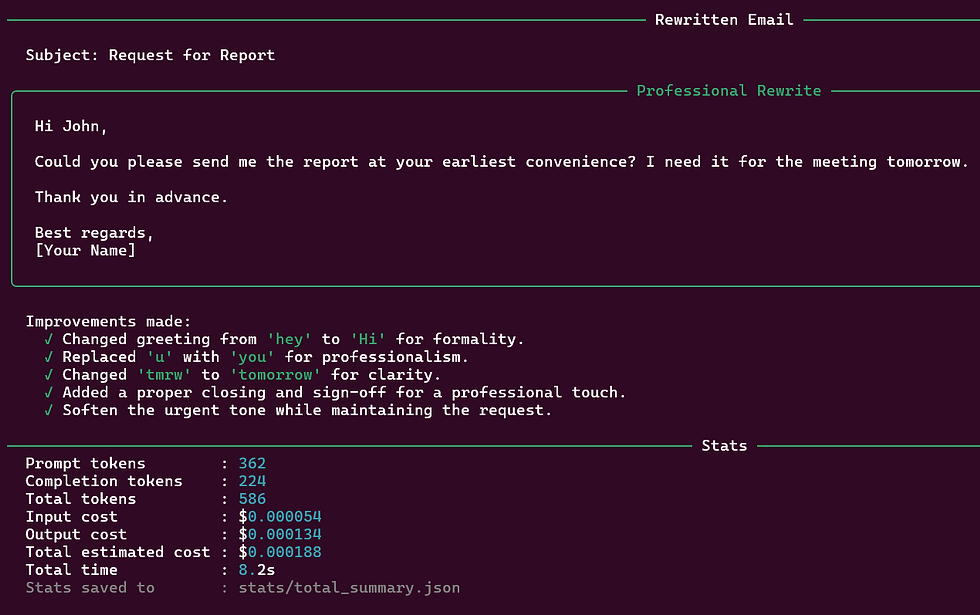
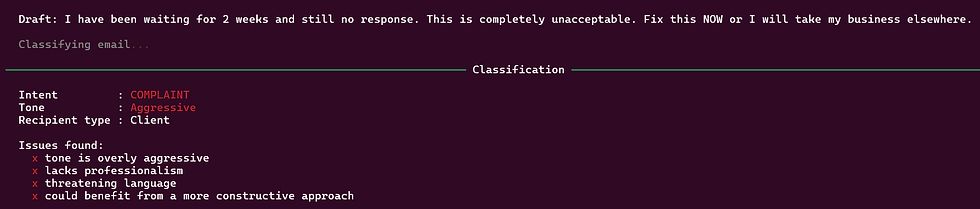
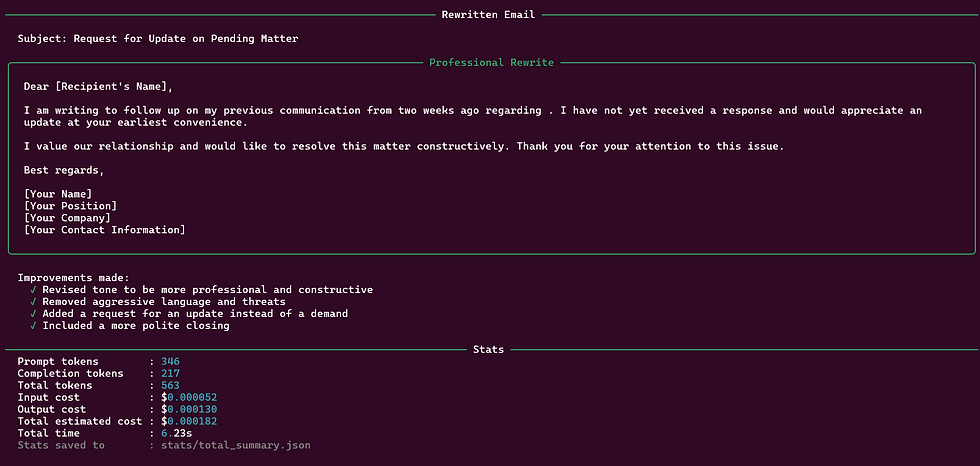
For a draft like "hey john, can u send me the report asap? need it for tmrw meeting. thanks", the pipeline produces:
Classification: - Intent: REQUEST - Tone: Too Casual - Recipient: Colleague - Issues: abbreviated words (u, tmrw, asap), informal greeting, no professional sign-off
Rewritten Email: - Subject: Request for Report — Tomorrow’s Meeting - Body: A concise, professional request with proper salutation and sign-off - Improvements: 5 bullet points listing exactly what was changed and why
Stats: - ~330 prompt tokens, ~235 completion tokens - Total cost ~$0.0002 per email - Total time ~7s (including server startup on first run)

total_summary.json file
[
{
"timestamp": "2026-06-11T15:31:28.810398",
"raw_email": "hey john, can u send me the report asap? need it for tmrw meeting. thanks",
"classification": {
"intent": "request",
"tone": "too casual",
"recipient_type": "colleague",
"issues": [
"Use of informal greeting ('hey')",
"Abbreviation ('u' instead of 'you')",
"Use of shorthand ('tmrw' instead of 'tomorrow')",
"Lack of formalities (no proper closing or sign-off)",
"Urgent tone could be softened for clarity"
]
},
"rewrite": {
"subject": "Request for Report",
"body": "Hi John,\n\nCould you please send me the report at your earliest convenience? I need it for the meeting tomorrow.\n\nThank you in advance.\n\nBest regards,\n[Your Name]",
"improvements": [
"Changed greeting from 'hey' to 'Hi' for formality.",
"Replaced 'u' with 'you' for professionalism.",
"Changed 'tmrw' to 'tomorrow' for clarity.",
"Added a proper closing and sign-off for a professional touch.",
"Soften the urgent tone while maintaining the request."
]
},
"prompt_tokens": 362,
"completion_tokens": 224,
"total_tokens": 586,
"input_cost": 5.4e-05,
"output_cost": 0.000134,
"total_cost": 0.000188,
"total_time_seconds": 8.2
},
....
]Who Can Benefit
Professionals who write many external emails and want a quick tone and clarity check
Non-native English speakers who want help achieving the right level of formality
Developers learning how to build multi-agent pipelines with real inter-agent HTTP communication
Teams who want to understand A2A architecture before scaling to production deployments
How Codersarts Can Help
Building production multi-agent systems requires solid understanding of agent communication protocols, async Python, API integration, and system design. If you need help building a custom A2A pipeline for your use case (email automation, document processing, customer support, or something entirely different), Codersarts offers end-to-end development and mentorship support.
Custom multi-agent system development tailored to your use case
One-on-one mentorship and code reviews
Project-based learning with real-world applications
Get in touch: codersarts.com | contact@codersarts.com




Comments