Build a Cost-Efficient Writing Quality Checker with Tiered Model Routing and OpenAI
- Jun 11
- 11 min read
Introduction
Not every piece of text needs the most powerful language model to check it. A short sentence with a grammar error can be caught by a fast, cheap model in under a second. Only long, complex writing with structural and coherence problems genuinely benefits from the most capable model available.
Tiered model routing applies this logic systematically. Short to medium text (up to 100 words) goes to GPT-4o-mini for grammar and clarity. If it detects structural or coherence problems, it escalates to GPT-4o for a full rewrite. Long text goes directly to GPT-4o. The same quality output, at a fraction of the cost.
In this tutorial, we build a 2-tier Writing Quality Checker using OpenAI’s GPT-4o-mini and GPT-4o. The user types or pastes text in the terminal, and the agent checks it for grammar, clarity, style, and coherence — routing it to whichever tier is appropriate. For any text with corrections, it also produces a corrected or fully rewritten version. After every run, a stats record is appended to a local JSON file.

What We’re Building
The agent checks any text through two tiers, escalating only when necessary:
Tier | Model | Handles |
1 | GPT-4o-mini | Grammar, clarity, and tone — short to medium texts (≤100 words) |
2 | GPT-4o | Deep style, coherence, and flow analysis with full rewrite |
Escalation is driven by two factors: text length and issue severity. Short and medium text (≤100 words) starts at Tier 1. If Tier 1 detects structural or coherence problems, it escalates to Tier 2. Long text (>100 words) goes directly to Tier 2.
Tech Stack
Component | Tool |
AI Models | GPT-4o-mini (Tier 1), GPT-4o (Tier 2) |
API Client | openai Python SDK |
CLI Output | rich |
Env Management | python-dotenv |
Project Structure
tiered_router/
├── router_agent.py # 2-tier routing logic, stats saver
├── app.py # Terminal interface
├── requirements.txt # Dependencies
├── .env # API key and model config
└── stats/
└── total_summary.json # Auto-created; one record appended per run
Setting Up
1. Install Dependencies
pip install openai python-dotenv rich2. Configure Environment
Create a .env file in the project folder:
# OpenAI API key — get yours at https://platform.openai.com/api-keys
OPENAI_API_KEY=your_openai_api_key_here
# Tier 1 model — grammar and clarity check
FAST_MODEL=gpt-4o-mini
# Tier 2 model — deep style and coherence analysis
SMART_MODEL=gpt-4o
Building the Agent — router_agent.py
Imports and Configuration
We load credentials, define the two model names, attach call metadata for tracking, and set up cost-per-token rates for calculating spend after every API call.
import os # read environment variables
import json # parse JSON responses from the model
import time # measure wall-clock time per run
from pathlib import Path # cross-platform file paths
from datetime import datetime # ISO timestamp for each stats record
from dotenv import load_dotenv # inject .env file into os.environ
from openai import OpenAI # official OpenAI Python SDK
load_dotenv() # must run before os.getenv — reads .env into the process environment
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY", "") # falls back to empty string if not set
FAST_MODEL = os.getenv("FAST_MODEL", "gpt-4o-mini") # Tier 1 — cheap, fast grammar check
SMART_MODEL = os.getenv("SMART_MODEL", "gpt-4o") # Tier 2 — deep analysis and rewrite
client = OpenAI(api_key=OPENAI_API_KEY) # single client instance shared across both tiers
# Attached to every API call — lets you filter by project or environment in the OpenAI dashboard
CALL_METADATA = {
"dev_name": "Ganesh", # developer who made the call
"project": "codex-test", # project identifier
"environment": "local", # local / staging / production
"purpose": "testing", # why this call was made
}
# Cost per 1 million tokens — divide token count by 1,000,000 then multiply by rate
_PRICING = {
"gpt-4o-mini": {"input": 0.150, "output": 0.600}, # ~17x cheaper than GPT-4o on input
"gpt-4o": {"input": 2.500, "output": 10.000}, # highest quality, used only when needed
}
Stats Directory and Saver
We create stats/ once at import time and append one record per run — storing the original text, corrected or rewritten version (if any), token usage, and cost.
STATS_DIR = Path("stats") # path relative to wherever the script is run from
STATS_DIR.mkdir(exist_ok=True) # creates the folder on first run; no error if it already exists
def save_stats(data: dict) -> None:
path = STATS_DIR / "total_summary.json" # all runs accumulate in one file
history = [] # start with empty list in case file doesn't exist yet
if path.exists():
with open(path, encoding="utf-8") as f:
try:
history = json.load(f) # load all previous records so we can append to them
except json.JSONDecodeError:
history = [] # file exists but is corrupt — start fresh rather than crash
history.append(data) # add the new record to the list
with open(path, "w", encoding="utf-8") as f:
json.dump(history, f, indent=2, ensure_ascii=False) # write the full list back; ensure_ascii=False preserves unicode
Tier 1 — GPT-4o-mini Grammar and Clarity Check
clarity_check sends the text to GPT-4o-mini with a prompt that asks for issues, severity, suggestions, a corrected version of the text, and an escalation flag. The corrected field is always returned — it will be identical to the input if no corrections are needed, which lets the UI decide whether to show the correction panel. Setting escalate=true signals the router that Tier 2 is needed for structural or coherence problems.
# System prompt for Tier 1 — instructs the model to return strict JSON
# escalate=true means the text needs structural work beyond grammar fixes
_FAST_PROMPT = (
"You are a writing quality assistant. "
"Check the given text for grammar errors, clarity issues, and tone problems. "
"Reply ONLY in JSON: "
"{\"issues\": [\"list of issues found, or empty list if none\"], "
"\"severity\": \"none|minor|moderate|major\", "
"\"suggestions\": [\"list of concrete suggestions, or empty list if none\"], "
"\"corrected\": \"the corrected version of the text (identical to input if no corrections needed)\", "
"\"escalate\": true|false}. "
"Set escalate=true only if the text has structural, coherence, or deep style issues "
"that need a full rewrite. Set escalate=false for grammar-only or minor clarity fixes."
)
def clarity_check(text: str) -> dict:
response = client.chat.completions.create(
model=FAST_MODEL, # gpt-4o-mini — fast and cost-efficient
messages=[
{"role": "system", "content": _FAST_PROMPT}, # sets the model's behaviour
{"role": "user", "content": f"Text to check:\n{text}"}, # the user's text to analyse
],
response_format={"type": "json_object"}, # forces valid JSON — prevents markdown code fences in the response
max_tokens=300, # enough for issues + suggestions + corrected text for short inputs
metadata=CALL_METADATA, # attached for dashboard tracking
)
raw = response.choices[0].message.content or "{}" # content is None if the model returned nothing
try:
parsed = json.loads(raw) # parse the JSON string into a Python dict
except json.JSONDecodeError:
# malformed response — fall back to safe defaults so the app keeps running
parsed = {"issues": [], "severity": "none", "suggestions": [], "corrected": "", "escalate": False}
usage = response.usage # prompt_tokens + completion_tokens
rates = _PRICING.get(FAST_MODEL, _PRICING["gpt-4o-mini"]) # look up pricing for the model used
return {
"tier": 1, # Tier 1 handled this request
"issues": parsed.get("issues", []), # list of grammar/clarity problems found
"severity": parsed.get("severity", "none"), # none | minor | moderate | major
"suggestions": parsed.get("suggestions", []), # concrete fix suggestions
"rewrite": parsed.get("corrected", ""), # corrected text — stored as "rewrite" so both tiers share one key name
"escalate_to": 2 if parsed.get("escalate") else None, # 2 = send to GPT-4o; None = stay at Tier 1
"prompt_tokens": usage.prompt_tokens, # tokens used for the system + user messages
"completion_tokens": usage.completion_tokens, # tokens used for the model's response
"input_cost": round((usage.prompt_tokens / 1_000_000) * rates["input"], 6), # cost for input tokens
"output_cost": round((usage.completion_tokens / 1_000_000) * rates["output"], 6), # cost for output tokens
}
Tier 2 — GPT-4o Deep Review and Rewrite
deep_review performs a full analysis covering grammar, style, coherence, flow, and readability. It always returns a rewrite field — an improved version of the entire text.
When called after Tier 1 escalation, it receives the prior issues so it can focus on what still needs fixing.
# System prompt for Tier 2 — broader scope than Tier 1, always produces a full rewrite
_DEEP_PROMPT = (
"You are a senior writing coach. "
"Perform a deep analysis of the text covering grammar, style, coherence, flow, and readability. "
"Reply ONLY in JSON: "
"{\"issues\": [\"detailed list of issues\"], \"severity\": \"minor|moderate|major\", "
"\"suggestions\": [\"detailed improvement suggestions\"], "
"\"rewrite\": \"improved version of the full text\"}."
)
def deep_review(text: str, prior_issues: list) -> dict:
context = text
if prior_issues:
# Append Tier 1's findings so GPT-4o does not repeat the same flags
context += f"\n\n[Prior checks flagged: {'; '.join(prior_issues)}]"
response = client.chat.completions.create(
model=SMART_MODEL, # gpt-4o — best quality, used only when needed
messages=[
{"role": "system", "content": _DEEP_PROMPT}, # senior writing coach persona
{"role": "user", "content": f"Text to review:\n{context}"}, # text + optional prior issues
],
response_format={"type": "json_object"}, # strict JSON — prevents the model adding prose outside the dict
max_tokens=800, # higher limit to allow a full rewrite of longer texts
metadata=CALL_METADATA, # dashboard tracking
)
raw = response.choices[0].message.content or "{}"
try:
parsed = json.loads(raw) # parse the model's JSON response
except json.JSONDecodeError:
# safe fallback — return empty fields instead of crashing
parsed = {"issues": [], "severity": "minor", "suggestions": [], "rewrite": ""}
usage = response.usage
rates = _PRICING.get(SMART_MODEL, _PRICING["gpt-4o"]) # look up GPT-4o pricing
return {
"tier": 2, # Tier 2 handled this request
"issues": parsed.get("issues", []), # detailed issue list from GPT-4o
"severity": parsed.get("severity", "minor"), # overall severity of problems
"suggestions": parsed.get("suggestions", []), # detailed improvement suggestions
"rewrite": parsed.get("rewrite", ""), # full improved version of the text
"prompt_tokens": usage.prompt_tokens,
"completion_tokens": usage.completion_tokens,
"input_cost": round((usage.prompt_tokens / 1_000_000) * rates["input"], 6),
"output_cost": round((usage.completion_tokens / 1_000_000) * rates["output"], 6),
}
The Router — check_writing
check_writing is the single entry point. It counts words to decide the starting tier, calls clarity_check or deep_review accordingly, and fires the on_progress callback once with the final tier that handled the text. Token usage and cost are accumulated across all API calls made in a single run.
def check_writing(text: str, on_progress=None) -> dict:
start_time = time.time() # record start so we can measure total wall-clock time
word_count = len(text.split()) # simple whitespace split — fast and good enough for routing
# Accumulators — added to after each API call so the stats record reflects total spend for the run
total_prompt_tokens = 0
total_completion_tokens = 0
total_input_cost = 0.0
total_output_cost = 0.0
if word_count > 100:
# Long text — skip Tier 1 and go directly to GPT-4o for full analysis
result = deep_review(text, []) # empty prior_issues — no Tier 1 ran
total_prompt_tokens += result.pop("prompt_tokens", 0) # pop removes the key from result before it's returned
total_completion_tokens += result.pop("completion_tokens", 0)
total_input_cost += result.pop("input_cost", 0.0)
total_output_cost += result.pop("output_cost", 0.0)
else:
# Short/medium text — start with Tier 1 (GPT-4o-mini grammar check)
result = clarity_check(text)
total_prompt_tokens += result.pop("prompt_tokens", 0)
total_completion_tokens += result.pop("completion_tokens", 0)
total_input_cost += result.pop("input_cost", 0.0)
total_output_cost += result.pop("output_cost", 0.0)
if result.get("escalate_to") == 2:
# Tier 1 flagged structural or coherence issues — escalate to GPT-4o for a full rewrite
prior = result.get("issues", []) # pass Tier 1's findings so GPT-4o doesn't repeat them
result = deep_review(text, prior) # result is now replaced with Tier 2's response
total_prompt_tokens += result.pop("prompt_tokens", 0)
total_completion_tokens += result.pop("completion_tokens", 0)
total_input_cost += result.pop("input_cost", 0.0)
total_output_cost += result.pop("output_cost", 0.0)
if on_progress:
on_progress(result.get("tier", 1)) # fires once — tells the UI which tier produced the final result
elapsed = round(time.time() - start_time, 2) # total seconds for this run
total_cost = round(total_input_cost + total_output_cost, 6) # combined spend across all API calls
stats_record = {
"timestamp": datetime.now().isoformat(), # when this run happened
"tier_used": result.get("tier"), # 1 or 2 — the tier that produced the final result
"word_count": word_count, # number of words in the input
"severity": result.get("severity", "none"), # none | minor | moderate | major
"issues_found": len(result.get("issues", [])), # total number of issues identified
"text": text, # original input — stored for reference
"rewrite": result.get("rewrite", ""), # corrected or rewritten text (empty if no changes)
"prompt_tokens": total_prompt_tokens, # total input tokens across all tiers
"completion_tokens": total_completion_tokens, # total output tokens across all tiers
"total_tokens": total_prompt_tokens + total_completion_tokens,
"input_cost": round(total_input_cost, 6), # cost for all prompt tokens
"output_cost": round(total_output_cost, 6), # cost for all completion tokens
"total_cost": total_cost, # total spend for this run in USD
"total_time_seconds": elapsed, # wall-clock time from call to result
}
save_stats(stats_record) # append this record to stats/total_summary.json
result["stats"] = stats_record # attach stats to the result so app.py can display them
return result
Building the CLI — app.py
The terminal interface accepts a single line of input per run. Issues are displayed as a bullet list, suggestions as another list, and the corrected or rewritten text appears in a green bordered panel — but only when the output differs from the original input.
import sys # used for KeyboardInterrupt / EOFError exit
from dotenv import load_dotenv # ensures .env is loaded even when app.py is the entry point
from rich.console import Console # rich terminal output with colour support
from rich.panel import Panel # bordered panel for the rewrite display
from rich.text import Text # (imported for optional future use)
from router_agent import check_writing # the single entry point into the routing logic
load_dotenv() # load .env here too — safe to call twice, second call is a no-op
console = Console() # global console instance used for all terminal output
# Maps tier number → (display label, rich colour style, model name)
# Used in on_progress and print_result to render consistent tier indicators
TIER_STYLE = {
1: ("[T1]", "bold blue", "GPT-4o-mini"), # Tier 1 shown in blue
2: ("[T2]", "bold magenta", "GPT-4o"), # Tier 2 shown in magenta
}
# Maps severity string → rich colour — used to colour the severity line in the result
SEVERITY_STYLE = {
"none": "green", # no issues — safe to use as-is
"minor": "yellow", # small grammar fixes
"moderate": "orange3", # noticeable clarity or tone problems
"major": "bold red", # significant structural or coherence issues
}
on_progress is called once by the router after all processing is done, so only one tier label appears per run:
def on_progress(tier: int):
label, style, name = TIER_STYLE[tier] # unpack label, colour, and model name for this tier
console.print(f" [{style}]{label} {name}[/{style}] processing...") # e.g. [T1] GPT-4o-mini processing...
print_result formats each section and suppresses the correction panel when the corrected text is identical to the original:
def print_result(result: dict):
tier = result.get("tier", 1) # which tier produced this result
label, style, name = TIER_STYLE[tier] # display label, colour, model name
issues = result.get("issues", []) # list of problems found
suggestions = result.get("suggestions", []) # list of suggested fixes
severity = result.get("severity", "none") # overall severity level
rewrite = result.get("rewrite", "") # corrected or rewritten text
stats = result.get("stats", {}) # token counts, cost, timing
sev_style = SEVERITY_STYLE.get(severity, "white") # colour for the severity line
console.print()
console.rule("[bold]Result[/bold]")
console.print()
console.print(f" Handled by : [{style}]{label} {name}[/{style}]") # e.g. [T2] GPT-4o
console.print(f" Severity : [{sev_style}]{severity.upper()}[/{sev_style}]") # e.g. MODERATE in orange
console.print(f" Word count : {stats.get('word_count', 0)}") # word count of the input
if issues:
console.print("\n [bold]Issues found:[/bold]")
for issue in issues:
console.print(f" [red]x[/red] {issue}") # red x bullet for each issue
if suggestions:
console.print("\n [bold]Suggestions:[/bold]")
for suggestion in suggestions:
console.print(f" [yellow]>[/yellow] {suggestion}") # yellow arrow for each suggestion
# Compare corrected text to original — only show the panel if something actually changed
original_text = stats.get("text", "")
if rewrite and rewrite.strip() != original_text.strip():
console.print()
console.print(Panel(
rewrite,
title="[bold]Corrected / Rewritten Text[/bold]",
border_style="green", # green border signals a positive/fixed result
padding=(1, 2), # one line top/bottom, two chars left/right
))
console.print()
console.rule("[bold]Stats[/bold]")
console.print(
f" Prompt tokens : {stats.get('prompt_tokens', 0)}\n" # tokens sent to the model
f" Completion tokens : {stats.get('completion_tokens', 0)}\n" # tokens in the model's response
f" Total tokens : {stats.get('total_tokens', 0)}\n" # combined token count
f" Input cost : ${stats.get('input_cost', 0):.6f}\n" # cost for prompt tokens
f" Output cost : ${stats.get('output_cost', 0):.6f}\n" # cost for completion tokens
f" Total estimated cost : [bold]${stats.get('total_cost', 0):.6f}[/bold]\n" # total spend in USD
f" Total time : {stats.get('total_time_seconds', 0)}s\n" # wall-clock time
f" [dim]Stats saved to : stats/total_summary.json[/dim]" # reminder where the record was written
)
console.print()
The main loop reads one line per run:
def main():
print_header() # prints the title rule and tier subtitle
console.print(" Type or paste your text and press Enter to submit.")
console.print(" Type [bold]exit[/bold] or [bold]quit[/bold] to stop.\n")
while True:
try:
text = input(" Input: ").strip() # single-line input — strip removes leading/trailing whitespace
except (KeyboardInterrupt, EOFError):
# Ctrl+C or Ctrl+D — exit cleanly without a traceback
console.print("\n Goodbye.")
break
if not text:
continue # user pressed Enter on an empty line — prompt again
if text.lower() in ("exit", "quit"):
console.print(" Goodbye.")
break
console.print() # blank line before the processing indicator
try:
result = check_writing(text, on_progress=on_progress) # run the 2-tier router
except Exception as exc:
console.print(f" [red]Error: {exc}[/red]") # show error but keep the loop running
continue
print_result(result) # format and display the full result
console.rule()
console.print()
if __name__ == "__main__":
main()
Running the App
python app.pyType or paste your text and press Enter. The agent routes it to the appropriate tier and prints the result.
Sample Inputs and What to Expect

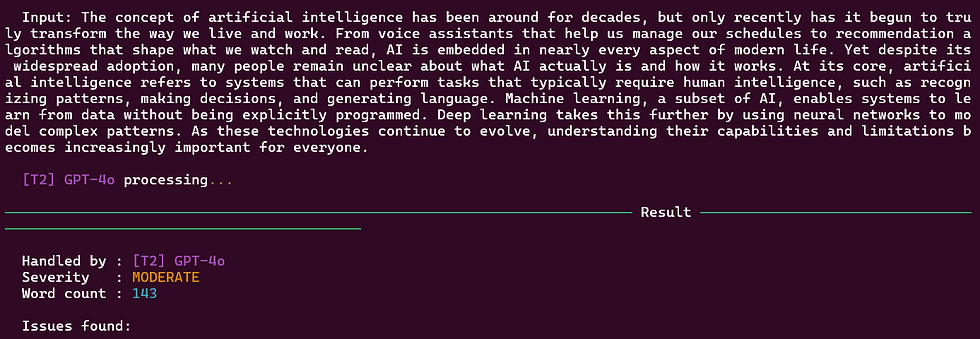



Who Can Benefit
Students and writers who want instant feedback on grammar and style without paying for premium tools
Developers building writing assistants who want a cost-aware routing layer rather than sending everything to GPT-4o
Content teams who need quick quality checks on short copy but deeper analysis on long-form articles
Non-native English speakers who write in English professionally and want detailed correction with rewrites
How Codersarts Can Help
Building production AI systems with intelligent routing, cost tracking, and real-time terminal output requires careful architecture decisions. If you need help implementing a similar pipeline for your use case (writing assistance, document review, content moderation, or something entirely different), Codersarts offers end-to-end development support and one-on-one mentorship.
Custom AI agent development tailored to your workflow
Code reviews and architecture guidance
Project-based learning with real-world applications
Get in touch: codersarts.com | contact@codersarts.com




Comments