Name Entity Recognition(NER)
- Sep 4, 2020
- 3 min read
Updated: Mar 25, 2021
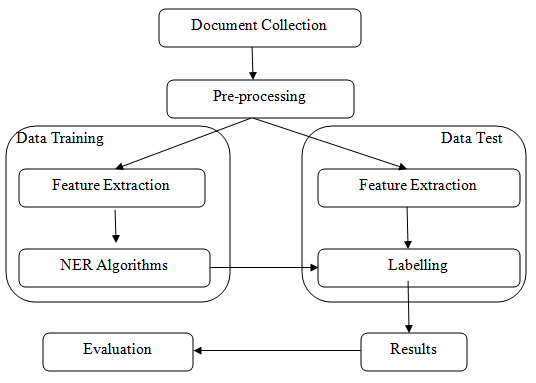

(NER)is probably the first step towards information extraction that seeks to locate and classify named entities in text into pre-defined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc. NER is used in many fields in Natural Language Processing (NLP), and it can help to answer many real-world questions. Named-entity recognition (NER)goes by many names such as entity identification, entity chunking, or entity extraction is a task involving extraction of information from a corpus of textual data. NER aims to locate and classify named entity mentioned in unstructured text into pre-defined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
This article describes how to build a named entity recognizer with NLTK and SpaCy, to identify the names of things, such as persons, organizations, or locations in the raw text.
Dependencies:
nltk
spacy
collections
en_core_web_sm
Importing The libraries:
import nltk
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
import spacy
from spacy import displacy
from collections import Counter
import en_core_web_sm
from nltk.chunk import conlltags2tree, tree2conlltags
from pprint import pprintInformation Extraction
This sentence has been taken “European authorities fined Google a record $5.1 billion on Wednesday for abusing its power in the mobile phone market and ordered the company to alter its practices.”
nltk.download('averaged_perceptron_tagger')
text = '''European authorities fined Google a record $5.1 billion on Wednesday for
abusing its power in the mobile phone market and ordered the company to alter its practices'''O/P:
[nltk_data] Downloading package punkt to /home/codersarts/nltk_data... [nltk_data] Package punkt is already up-to-date! [nltk_data] Downloading package averaged_perceptron_tagger to [nltk_data] /home/codersarts/nltk_data... [nltk_data] Package averaged_perceptron_tagger is already up-to- [nltk_data] date!
True
Tokenization & Parts Of Speech tagging: This involves splitting the sentences into word tokens and extraction pos features from them.
tokens = nltk.word_tokenize(text)
pos_text = nltk.pos_tag(tokens)
pos_text[:5]O/p:
[('European', 'JJ'), ('authorities', 'NNS'), ('fined', 'VBD'), ('Google', 'NNP'), ('a', 'DT')]
Tree Visualization:
The next portion involves visualization of the relation between different postages in a tree representation
We get a list of tuples containing the individual words in the sentence and they're associated part-of-speech.
Now we’ll implement noun phrase chunking to identify named entities using a regular expression consisting of rules that indicate how sentences should be chunked.
Our chunk pattern consists of one rule, that a noun phrase, NP, should be formed whenever the chunker finds an optional determiner, DT, followed by any number of adjectives, JJ, and then a noun, NN.
pattern = 'NP: {<DT>?<JJ>*<NN>}'
content_parser = nltk.RegexpParser(pattern)
parsed_tree = content_parser.parse(pos_text)
parsed_tree
The output can be read as a tree or a hierarchy with S as the first level, denoting sentence. we can also display it graphically.
iob_tagged = tree2conlltags(cs)
pprint(iob_tagged)O/p:
[('European', 'JJ', 'O'), ('authorities', 'NNS', 'O'), ('fined', 'VBD', 'O'), ('Google', 'NNP', 'O'), ('a', 'DT', 'B-NP'), ('record', 'NN', 'I-NP'), ('$', '$', 'O'), ('5.1', 'CD', 'O'), ('billion', 'CD', 'O'), ('on', 'IN', 'O'), ('Wednesday', 'NNP', 'O'), ('for', 'IN', 'O'), ('abusing', 'VBG', 'O'), ('its', 'PRP$', 'O'), ('power', 'NN', 'B-NP'), ('in', 'IN', 'O'), ('the', 'DT', 'B-NP'), ('mobile', 'JJ', 'I-NP'), ('phone', 'NN', 'I-NP'), ('market', 'NN', 'B-NP'), ('and', 'CC', 'O'), ('ordered', 'VBD', 'O'), ('the', 'DT', 'B-NP'), ('company', 'NN', 'I-NP'), ('to', 'TO', 'O'), ('alter', 'VB', 'O'), ('its', 'PRP$', 'O'), ('practices', 'NNS', 'O')]
IOB tags have become the standard way to represent chunk structures in files, and we will also be using this format.
In this representation, there is one token per line, each with its part-of-speech tag and its named entity tag. Based on this training corpus, we can construct a tagger that can be used to label new sentences.
Read a file from local:
file = open(fileloc, mode='rt', encoding='utf-8')
article = file.read()
file.close()Loading Model The model I have used for the sake of this article is en_core_web_sm, which comes alongside SpaCy.It consists of English multi-task CNN trained on OntoNotes, with GloVe vectors trained on Common Crawl. Assigns word vectors, context-specific token vectors, POS tags, dependency parse, and named entities.
model = en_core_web_sm.load()
doc = model(article)
pprint([(X.text, X.label_) for X in doc.ents])O/p:
[('Kamra', 'ORG'), ('Goswami', 'GPE'), ('IndiGo', 'GPE'), ('Tuesday', 'DATE'), ('Kamra', 'PERSON'), ('Goswami', 'PERSON'), ('20 seconds', 'TIME'), ('Mumbai', 'GPE'), ('Lucknow', 'GPE'), ('Kunal Kamra', 'PERSON'), ('a period of six months', 'DATE')]
Named-Entity-Recognition on an article of Indian Express. It should be noted that these models are not perfect but provide near to perfect results.
displacy.render(doc, jupyter=True, style='ent')
So in this manner, you can build a Named Entity Recognition.
For Code Refer this Link:
Thank you! for Reading
Happy Learning!




Comments