Credit Card Fraud Detection dataset - Classification
- Jan 12, 2022
- 2 min read

Description :
It is important that credit card companies are able to recognize fraudulent credit card transactions so that customers are not charged for items that they did not purchase.
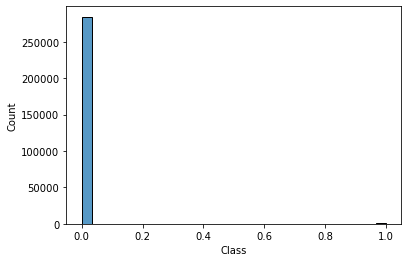
The dataset contains transactions made by credit cards in September 2013 by European cardholders. This dataset presents transactions that occurred in two days, where we have 492 frauds out of 284,807 transactions. The dataset is highly unbalanced, the positive class (frauds) account for 0.172% of all transactions.
Recommended Model :
Algorithms to be used: KMeans, KNN, Agglomerative clustering etc.
Recommended Project :
Customer Segmentation.
Dataset link:
Overview of data
Detailed overview of dataset:
- Rows = 284,807
- Columns = 31
It contains only numerical input variables which are the result of a PCA transformation.
Unfortunately, due to confidentiality issues, the original features and more background information about the data is not provided
.
Features V1, V2, … V28 are the principal components obtained with PCA, the only features which have not been transformed with PCA are 'Time' and 'Amount'. Feature 'Time' contains the seconds elapsed between each transaction and the first transaction in the dataset. The feature 'Amount' is the transaction Amount, this feature can be used for example- dependent cost-sensitive learning. Feature 'Class' is the response variable and it takes value 1 in case of fraud and 0 otherwise.
EDA [CODE]
import pandas as pd
# load data data = pd.read_csv('creditcard.csv')
data.head()
# check details of the dataframe
data.info()
# statistical information about the dataset
data.describe()
# data distribution
import seaborn as sns
import matplotlib.pyplot as plt
data = data.dropna() # removing missing value
for i in data.columns[1:]:
sns.histplot(data[i], bins=30,kde=False)
plt.show()
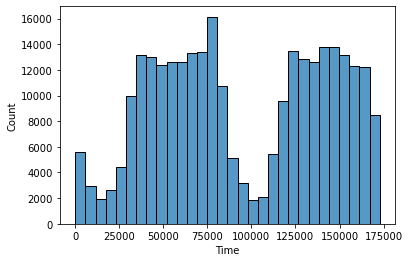




























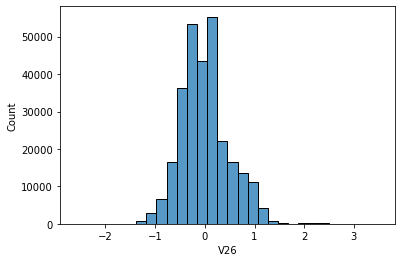

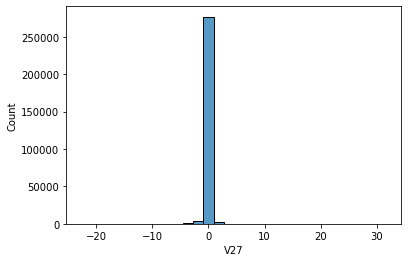

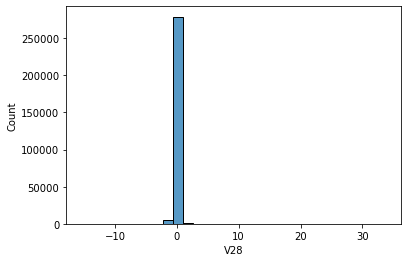

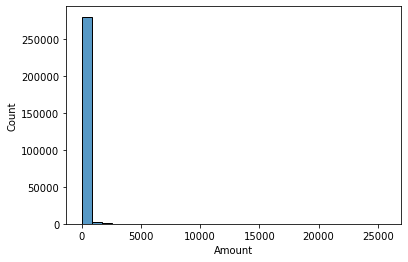

-
Other datasets for classification:
If you need implementation for any of the topics mentioned above or assignment help on any of its variants, feel free to contact us



Comments