Creating a Text-to-Speech Web Application with Streamlit and SpeechT5
- Aug 20, 2024
- 7 min read
Imagine converting your written text into lifelike speech with just a few clicks. With advancements in AI and natural language processing, this is now possible. In this tutorial, we'll guide you through building a Text-to-Speech (TTS) application using Streamlit, a powerful Python framework for creating web apps, and SpeechT5, a state-of-the-art TTS model from Hugging Face Transformers. By the end of this guide, you'll have a fully functional web app that takes user input text and converts it into downloadable audio.

Introduction
Text-to-Speech technology has revolutionized the way we interact with devices, making information more accessible, particularly for individuals with visual impairments. It also plays a significant role in virtual assistants, audiobooks, and many other applications. The SpeechT5 model from Microsoft, available through Hugging Face Transformers, is a powerful tool for generating high-quality speech from text. In this tutorial, we'll integrate this model into a simple Streamlit web app.
What You Will Learn
In this tutorial, you will learn:
How to set up a Streamlit web application.
How to load and use the SpeechT5 model for text-to-speech conversion.
How to handle user input and generate speech in real-time.
How to provide downloadable audio files to users.
Prerequisites
Before you begin, ensure you have the following:
Basic knowledge of Python programming.
Streamlit installed in your Python environment (pip install streamlit).
Hugging Face Transformers installed (pip install transformers).
SoundFile library installed (pip install soundfile).
Setting Up the Environment
First, let's make sure you have all the necessary libraries installed. Run the following commands in your terminal:
pip install streamlit transformers soundfileThese commands will install Streamlit for creating the web app, the Transformers library for the TTS model, and SoundFile for saving the generated audio.
Understanding the Code
Let's dive into the code and understand how each part contributes to the final application.
1. Importing Required Libraries
import streamlit as st
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan
from datasets import load_dataset
import torch
import soundfile as sfHere, we import the necessary libraries:
streamlit: Used to create the web interface.
SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan: Components of the SpeechT5 model used for processing text, generating speech, and vocoding.
load_dataset: To load datasets, particularly the speaker embeddings for generating personalized speech.
torch: The core library for handling tensors, essential for working with the model.
soundfile: Used for saving the generated speech as an audio file.
2. Loading the Text-to-Speech Model
# Load the TTS model
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")This section of the code loads the pre-trained SpeechT5 model components:
SpeechT5Processor: Processes the input text into a format suitable for the model.
SpeechT5ForTextToSpeech: The model that generates the speech from the processed text.
SpeechT5HifiGan: A vocoder that enhances the quality of the generated speech, making it sound more natural.
3. Loading Speaker Embeddings
# load xvector containing speaker's voice characteristics from a dataset
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)The model uses speaker embeddings to create speech that mimics the characteristics of a specific speaker's voice. Here, we load these embeddings from a pre-existing dataset. The embeddings help personalize the generated speech, making it more realistic and tailored to a specific voice.
4. Defining the Audio Download Function
# Function to generate a download link for the audio file
def get_audio_download_link(filename):
href = f'<a href="{filename}">Download audio</a>'
return hrefThis function generates an HTML link for downloading the generated audio file. It's used later in the Streamlit app to provide users with an easy way to download the speech file.
5. Building the Streamlit Web App
# Streamlit app
st.title("Text-to-Speech")
# User input
text = st.text_area("Enter text to convert to speech")
if st.button("Generate Speech"):
if text:
# Generate speech
inputs = processor(text=text, return_tensors="pt")
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)
# Save the speech
sf.write("speech.wav", speech.numpy(), samplerate=16000)
# Display audio player
st.audio("speech.wav", format="audio/wav")
# Download link
st.markdown('<a href="speech.wav">Download audio</a>', unsafe_allow_html=True)This section is where the main functionality of the web app is implemented:
st.title("Text-to-Speech"): Sets the title of the web page.
st.text_area("Enter text to convert to speech"): Creates a text area for users to input the text they want to convert into speech.
st.button("Generate Speech"): Adds a button that users can click to trigger the speech generation process.
Lets Understand Line By Line code
Streamlit App Initialization and User Interface
# Streamlit app
st.title("Text-to-Speech")st.title("Text-to-Speech"): This line sets the title of the Streamlit web app. The st.title() function displays a large, bold title at the top of the page, making it clear to users what the application does. In this case, the title is "Text-to-Speech," which immediately informs users that the app is designed to convert text input into spoken words.
User Input Section
# User input
text = st.text_area("Enter text to convert to speech")text = st.text_area("Enter text to convert to speech"): This line creates a text input area where users can type the text they want to convert into speech. The st.text_area() function displays a multi-line text box on the web page, and the prompt "Enter text to convert to speech" guides the user on what to do. The input from this text area is stored in the variable text, which will be used later in the code.
Button and Speech Generation
if st.button("Generate Speech"):
if text:if st.button("Generate Speech"):: This line adds a button to the Streamlit app labeled "Generate Speech." When the user clicks this button, it triggers the code inside the if block to execute. This is how users start the process of converting the entered text into speech.
if text:: This conditional checks whether the text variable (which holds the user input) is not empty. This ensures that the speech generation code only runs if the user has actually entered some text.
Text-to-Speech Processing
# Generate speech
inputs = processor(text=text, return_tensors="pt")
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)inputs = processor(text=text, return_tensors="pt"): This line processes the input text using the SpeechT5Processor. The text parameter is the user-entered text, and return_tensors="pt" specifies that the output should be returned as PyTorch tensors. This is necessary because the TTS model expects its inputs in tensor format for processing.
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder): This line generates the actual speech from the processed text. The model.generate_speech() function takes the processed text (inputs["input_ids"]), the speaker_embeddings (which determine the voice characteristics), and the vocoder (which refines the generated audio to make it sound more natural). The result is stored in the speech variable, which contains the generated audio data.
Saving and Playing the Generated Speech
# Save the speech
sf.write("speech.wav", speech.numpy(), samplerate=16000)sf.write("speech.wav", speech.numpy(), samplerate=16000): This line saves the generated speech as a WAV audio file. The sf.write() function from the soundfile library writes the audio data to a file. The file is named "speech.wav", and speech.numpy() converts the speech data from a PyTorch tensor to a NumPy array, which is the format required by soundfile. The samplerate=16000 parameter sets the audio sample rate to 16 kHz, a common setting for speech audio.
Displaying the Audio Player
# Display audio player
st.audio("speech.wav", format="audio/wav")st.audio("speech.wav", format="audio/wav"): This line adds an audio player to the Streamlit app that plays the generated speech. The st.audio() function takes the path to the audio file ("speech.wav") and the format of the audio (format="audio/wav"). Users can play the audio directly in the web app without needing to download it first.
Providing a Download Link
# Download link
st.markdown('<a href="speech.wav">Download audio</a>', unsafe_allow_html=True)st.markdown('<a href="speech.wav">Download audio</a>', unsafe_allow_html=True): This line creates a download link for the generated audio file. The st.markdown() function allows you to include custom HTML in the Streamlit app, and the <a> tag is used to create a clickable link. The href="speech.wav" attribute points to the saved audio file, and the text Download audio is what users will see and click to download the file. The unsafe_allow_html=True parameter is required to allow HTML content, which is typically restricted in Streamlit for security reasons.
When the "Generate Speech" button is clicked:
The text entered by the user is processed using SpeechT5Processor.
The processed text is passed through the TTS model to generate speech.
The generated speech is saved as a WAV file.
The audio file is then played back using st.audio.
A download link is provided so that the user can download the speech file.
Deploying the Application
To run the application, save the code to a file (e.g., app.py). In your terminal, navigate to the directory containing the file and run:
streamlit run app.pyThis command will start the Streamlit server, and a web browser window will open with your TTS application. You can now input text, generate speech, and download the audio file directly from the browser.
Now you can see we have just built a fully functional Text-to-Speech web application using Streamlit and SpeechT5. This application demonstrates how powerful and accessible AI has become, allowing you to transform text into lifelike speech with just a few lines of code.
This project is just the beginning. You can enhance the application by adding features such as:
Allowing users to choose different speaker embeddings for varied voice outputs.
Adding a user interface to adjust the speech rate or pitch.
Deploying the app on a cloud platform like Heroku or AWS to make it accessible to a wider audience.
Complete Code
import streamlit as st
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan
from datasets import load_dataset
import torch
import soundfile as sf
from datasets import load_dataset
# Load the TTS model
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
# load xvector containing speaker's voice characteristics from a dataset
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
# Function to generate a download link for the audio file
def get_audio_download_link(filename):
href = f'<a href="{filename}">Download audio</a>'
return href
# Streamlit app
st.title("Text-to-Speech")
# User input
text = st.text_area("Enter text to convert to speech")
if st.button("Generate Speech"):
if text:
# Generate speech
inputs = processor(text=text, return_tensors="pt")
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)
# Save the speech
sf.write("speech.wav", speech.numpy(), samplerate=16000)
# Display audio player
st.audio("speech.wav", format="audio/wav")
# Download link
st.markdown('<a href="speech.wav">Download audio</a>', unsafe_allow_html=True)
Output Screenshots

2.

3.
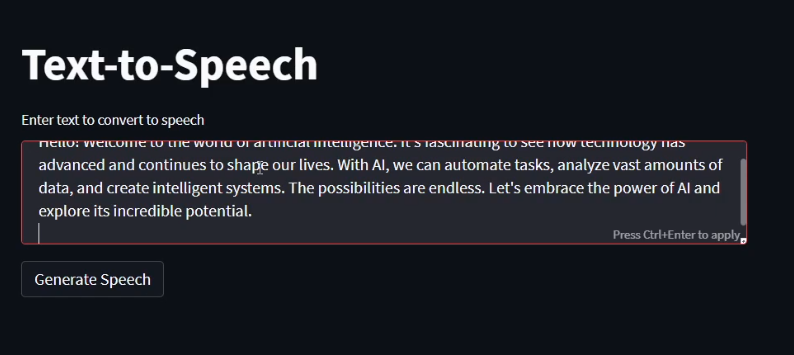
Project Demo Video
Text-to-Speech technology has a wide range of applications, from creating voiceovers to helping the visually impaired access written content. With this foundation, you can explore and innovate in the growing field of speech synthesis.
Happy coding!
For the complete solution or any assistance with creating a Text-to-Speech Web Application with Streamlit and SpeechT5, feel free to contact us.



Comments