Building a Fake News Detection Model Using Machine Learning
- Aug 26, 2024
- 5 min read
Fake news has become a significant issue in today’s digital age, where misinformation can spread rapidly through social media and online platforms. Detecting fake news is crucial for maintaining the integrity of information. This blog will guide you through building a fake news detection model using machine learning. The provided code in the fake_news.ipynb Jupyter Notebook covers data preprocessing, exploratory data analysis, model training, and evaluation using various machine learning algorithms.

Introduction
The goal of this project is to develop a machine learning model that can distinguish between real and fake news articles. The dataset includes labeled news articles, and we'll use machine learning techniques to classify these articles based on their content. We’ll explore multiple models, including Logistic Regression, Random Forest, and Gaussian Naive Bayes, and compare their performance.
What You Will Learn
By the end of this tutorial, you will learn:
How to preprocess text data for machine learning.
How to perform exploratory data analysis (EDA) on a text dataset.
How to train and evaluate multiple machine learning models.
How to use hyperparameter tuning to optimize model performance.
Prerequisites
Before starting, ensure you have the following installed:
Python
Jupyter Notebook
Required Python libraries (Pandas, Matplotlib, Scikit-learn, Seaborn, Joblib, etc.)
Understanding the Provided Code
Let’s go through the provided code step by step.
1. Importing the Required Libraries
import pandas as pd
import matplotlib.pyplot as plt
import numpy as npPandas: Used for data manipulation and analysis.
Matplotlib: Used for data visualization.
NumPy: Provides support for large, multi-dimensional arrays and matrices.
2. Loading the Data
train_df = pd.read_csv('train.csv')
test_df = pd.read_csv('test.csv')
submit_df = pd.read_csv('submit.csv')Loading CSV Files: The dataset is loaded from CSV files into Pandas DataFrames. The train.csv contains the training data, test.csv contains the test data, and submit.csv contains the submission format for predictions.
3. Visualizing the Data
train_df.head()
test_df.head()
submit_df.head()Displaying Data: The head() method is used to display the first few rows of each DataFrame, allowing us to inspect the data structure.
Output :



final_test_df = test_df.join(submit_df, rsuffix='_2')
final_test_df.drop(['id','id_2','title'],axis=1, inplace=True)
final_test_df = final_test_df.dropna()
final_test_df.head()Merging DataFrames: The test data is joined with the submission DataFrame. Unnecessary columns like id and title are dropped, and missing values are handled by removing rows with NaN values.
Output :

4. Exploratory Data Analysis (EDA)
Label Distribution
label_dist = train_df.label.value_counts()
labels = ['Original', 'Fake']
plt.pie(x=label_dist.values, labels=labels)
plt.ylabel('Count')
plt.title('Label/ Target Distribution')
plt.show()Pie Chart: A pie chart is created to visualize the distribution of labels (Original vs. Fake) in the training data. This helps us understand if the dataset is balanced.
Output :

Word Cloud for Frequent Words
from sklearn.feature_extraction.text import CountVectorizer
from wordcloud import WordCloud
def plot_word_cloud(df, name):
text = CountVectorizer(stop_words='english').fit(df['text'].tolist())
bag_of_words = text.transform(df['text'].tolist())
sum_words = bag_of_words.sum(axis=0)
words_freq = [(word, sum_words[0, idx]) for word, idx in text.vocabulary_.items()]
words_freq = sorted(words_freq, key=lambda x: x[1], reverse=True)[:50]
top_words = " ".join([i[0] for i in words_freq])
word_cloud = WordCloud(collocations=False, background_color='white').generate(top_words)
plt.imshow(word_cloud, interpolation='bilinear')
plt.title(f'{name}')
plt.axis("off")
plt.show()
plot_word_cloud(all_df, 'Frequent Words for all articles')
plot_word_cloud(fake_df, 'Frequent Words for all Fake articles')
plot_word_cloud(true_df, 'Frequent Words for all Original articles')Word Cloud: The function plot_word_cloud is used to visualize the most frequent words in the articles. Separate word clouds are generated for all articles, fake articles, and original articles. This helps us understand the common vocabulary used in different types of articles.
Output



Correlation Analysis
temp_df = train_df[['author', 'label']]
temp_df['author'] = pd.Categorical(temp_df['author']).codes
corr = temp_df.corr()
import seaborn as sns
sns.heatmap(corr, annot=True)
plt.show()Correlation Matrix: A correlation matrix is generated to examine the relationship between the author and label features. The matrix is visualized using a heatmap, providing insights into how these variables are related.
Output :
5. Machine Learning Model Training
Preprocessing the Data
from sklearn.feature_extraction.text import CountVectorizer
from scipy.sparse import csr_matrix, hstack
vectorized = CountVectorizer(strip_accents='ascii', stop_words='english')
train_df = train_df.dropna()
vector = vectorized.fit_transform(train_df['text'])
X_train, X_test, y_train, y_test = train_test_split(vector, train_df.label, test_size=0.2)
joblib.dump(vectorized, 'vectorizer.pkl')Text Vectorization: The text data is vectorized using CountVectorizer, which converts the text into a matrix of token counts. This matrix is then split into training and testing sets. The vectorizer object is saved for future use.
Output :

Logistic Regression Model
log_reg = LogisticRegression(C=1e-5, max_iter=5000, random_state=42)
log_reg.fit(X_train, y_train)
y_train_pred = log_reg.predict(X_train)
y_test_pred = log_reg.predict(X_test)
print("Training")
print(f"Accuracy: {accuracy_score(y_train, y_train_pred)} F1 Score: {f1_score(y_train, y_train_pred)}")
print("Classsification report")
print(classification_report(y_train, y_train_pred))
print("Testing")
print(f"Testing Accuracy: {accuracy_score(y_test, y_test_pred)} F1 Score: {f1_score(y_test, y_test_pred)}")
print("Classsification report")
print(classification_report(y_test, y_test_pred))
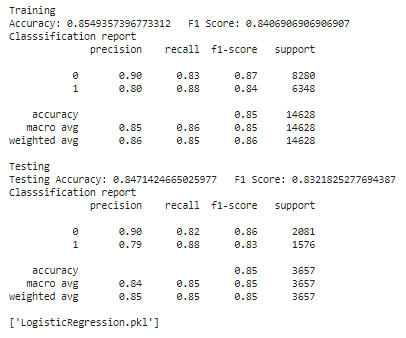
joblib.dump(log_reg, 'LogisticRegression.pkl')Training and Evaluation: The Logistic Regression model is trained on the vectorized text data. The model's performance is evaluated using accuracy and F1 score metrics, and a classification report is generated. The trained model is saved using joblib.
Output :
Random Forest Classifier
rfc = RandomForestClassifier(n_estimators=200, max_depth=25, random_state=42)
rfc.fit(X_train, y_train)
y_train_pred = rfc.predict(X_train)
y_test_pred = rfc.predict(X_test)
print("Training")
print(f"Accuracy: {accuracy_score(y_train, y_train_pred)} F1 Score: {f1_score(y_train, y_train_pred)}")
print("Classsification report")
print(classification_report(y_train, y_train_pred))
print("Testing")
print(f"Testing Accuracy: {accuracy_score(y_test, y_test_pred)} F1 Score: {f1_score(y_test, y_test_pred)}")
print("Classsification report")
print(classification_report(y_test, y_test_pred))
joblib.dump(rfc, 'RandomForestClassifier.pkl')Random Forest: The Random Forest Classifier is trained similarly, with evaluations on both the training and testing data. The model is saved for later use.
Output :

Gaussian Naive Bayes
vectorized_NB = CountVectorizer(strip_accents='ascii', stop_words='english', max_features=20000)
vector_NB = vectorized_NB.fit_transform(train_df['text'])
X_train_NB, X_test_NB, y_train_NB, y_test_NB = train_test_split(vector_NB, train_df.label, test_size=0.2)
gnb = GaussianNB(var_smoothing=1e-9)
gnb.fit(X_train_NB.toarray(), y_train_NB)
y_train_pred = gnb.predict(X_train_NB.toarray())
y_test_pred = gnb.predict(X_test_NB.toarray())
print("Training")
print(f"Accuracy: {accuracy_score(y_train_NB, y_train_pred)} F1 Score: {f1_score(y_train_NB, y_train_pred)}")
print("Classsification report")
print(classification_report(y_train_NB, y_train_pred))
print("Testing")
print(f"Testing Accuracy: {accuracy_score(y_test_NB, y_test_pred)} F1 Score: {f1_score(y_test_NB, y_test_pred)}")
print("Classsification report")
print(classification_report(y_test_NB, y_test_pred))
joblib.dump(gnb, 'GaussianNB.pkl')Gaussian Naive Bayes: Due to the large feature space, the Naive Bayes model is trained on a reduced set of features. The model’s performance is evaluated and saved.
Output :

6. Model Comparison
vector_2 = vectorized_NB.transform(final_test_df['text'])
log_pred = log_reg.predict(vector)
rfc_pred = rfc.predict(vector)
gnb_pred = gnb.predict(vector_2.toarray())
print("Logistic Regression Model")
print(f"Accuracy: {accuracy_score(final_test_df['label'], log_pred)} F1 Score: {f1_score(final_test_df['label'], log_pred)}")
print("Classsification report")
print(classification_report(final_test_df['label'], log_pred))
print('---')
print("Random Forest Classifier")
print(f"Accuracy: {accuracy_score(final_test_df['label'], rfc_pred)} F1 Score: {f1_score(final_test_df['label'], rfc_pred)}")
print("Classsification report")
print(classification_report(final_test_df['label'], rfc_pred))
print('---')
print("Guassian Navie Bayes")
print(f"Accuracy: {accuracy_score(final_test_df['label'], gnb_pred)} F1 Score: {f1_score(final_test_df['label'], gnb_pred)}")
print("Classsification report")
print(classification_report(final_test_df['label'], gnb_pred))Model Comparison: The performance of the Logistic Regression, Random Forest, and Gaussian Naive Bayes models is compared on the final test data. Accuracy and F1 scores are calculated, and classification reports are generated for each model.
Output :

7. Hyperparameter Tuning
Logistic Regression
param_grid = {'penalty': ['l1', 'l2'], 'C': [1e-7, 0.001, 0.01, 0.1, 1, 10, 100]}
logistic = LogisticRegression()
grid_search = GridSearchCV(logistic, param_grid, cv=5)
grid_search.fit(X_train, y_train)
print("Best parameters: {}".format(grid_search.best_params_))
print(f"Accuracy on test data: {grid_search.best_estimator_.score(vector_test, final_test_df['label'])}")Grid Search: The hyperparameters of the Logistic Regression model are tuned using Grid Search, which tests different combinations of parameters to find the best-performing model.
Output :

Random Forest and Gaussian Naive Bayes
Similar Tuning: The Random Forest and Gaussian Naive Bayes models are also tuned using Grid Search, optimizing their respective parameters to improve performance.
The provided code builds and evaluates multiple machine learning models to detect fake news articles. The Logistic Regression model performed best on the test dataset, achieving an F1 score of 70%. While hyperparameter tuning was applied, it led to overfitting in some cases, emphasizing the need for careful evaluation of models on unseen data.
This project demonstrates the entire pipeline of fake news detection, from data preprocessing and EDA to model training, evaluation, and tuning. By following this guide, you can develop and fine-tune your models for various text classification tasks, including fake news detection.
If you require any assistance with this project or Machine Learning projects, please do not hesitate to contact us. We have a team of experienced developers who specialize in Machine Learning and can provide you with the necessary support and expertise to ensure the success of your project. You can reach us through our website or by contacting us directly via email or phone.



Comments